2026

Authors: Mingyang Song, Yang Zhang, Siyu Tang, Tunc Ozan Aydin
We show that Dynamic Gaussian Splatting can be aggressively compressed by combining quantization-aware training with carefully structured motion vectors. The principle is borrowed from conventional video codecs: smoother content is cheaper to encode.
Authors: Xiaozhong Lyu*, Gen Li*, Zhiyin Qian, Xucong Zhang, Marc Pollefeys, Siyu Tang (*equal contribution; order interchangeable)
ReViV reconstructs viewer-centric human motion (body, hand, and gaze) and view-centric scene geometry (camera and depth) from a single egocentric RGB video in a unified feed-forward model.
Authors: Kaifeng Zhao, Mathis Petrovich, Haotian Zhang, Tingwu Wang, Siyu Tang, Davis Rempe
ARDY is an autoregressive diffusion model for interactive human motion generation that supports online text prompting and flexible long-horizon kinematic constraints with real-time responsiveness.
Authors: Joaquin Gajardo, Michele Volpi, Marko Mihajlovic, Siyu Tang, Lukas Roth, Sergey Prokudin
GrowFields models 4D plant growth by decomposing a plant into organs and evolving them with a shared, latent-conditioned neural velocity field that learns cross-organ growth priors while handling changing topology.

Authors: Rui Wang, Quentin Lohmeyer, Siyu Tang, Mirko Meboldt
Multi4D enables high-quality, efficient dynamic scene reconstruction via competitive multi-level specialization, and compact, high-accuracy 4D segmentation with fast inference.
Authors: Malte Prinzler, Paulo Gotardo, Siyu Tang, Timo Bolkart
Given calibrated multi-view images of human heads, MATCH infers static Gaussian splat textures in dense semantic correspondence.
Authors: Yiming Wang, Qihang Zhang, Shengqu Cai, Tong Wu, Jan Ackermann, Zhengfei Kuang, Yang Zheng, Frano Rajič, Siyu Tang, Gordon Wetzstein
Time- and camera-controlled 4D video generation that enables decoupled control over world time and camera pose from a single input video.
Authors: Yutong Chen, Yiming Wang, Xucong Zhang, Sergey Prokudin, Siyu Tang
GGPT can use reliable geometric guidance to augment various feed-forward method for 3D reconstruction.
Authors: Zhiyin Qian, Siwei Zhang, Bharat Lal Bhatnagar, Federica Bogo, Siyu Tang
Given a monocular video captured from a static camera, MoRo robustly reconstructs accurate and physically plausible human motion, even under challenging occlusion scenarios.
Authors: Xiaozhong Lyu, Korrawe Karunratanakul, Kaifeng Zhao, Siyu Tang
LaMP learns a robust latent motion prior with a part-based masked autoencoder, enabling optimization-based motion editing, blending, refinement, and collision avoidance.2025

Authors: Yiming Wang, Shaofei Wang, Marko Mihajlovic, Siyu Tang
Neural Texture Splatting is an expressive extension of 3D Gaussian Splatting that introduces a local neural RGBA field for each primitive.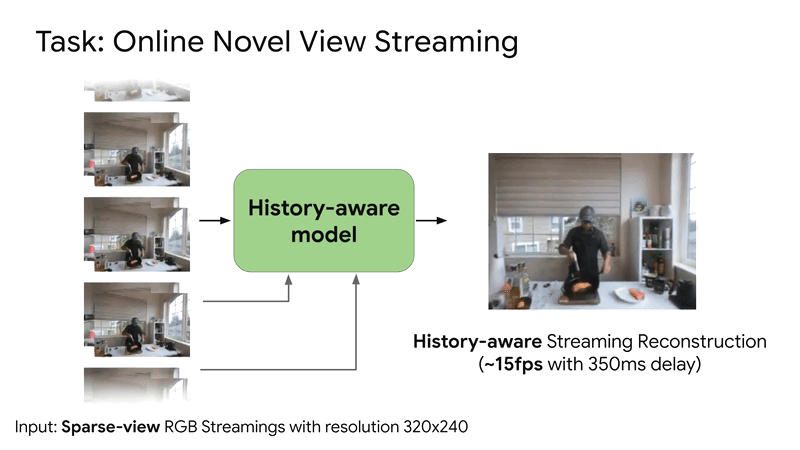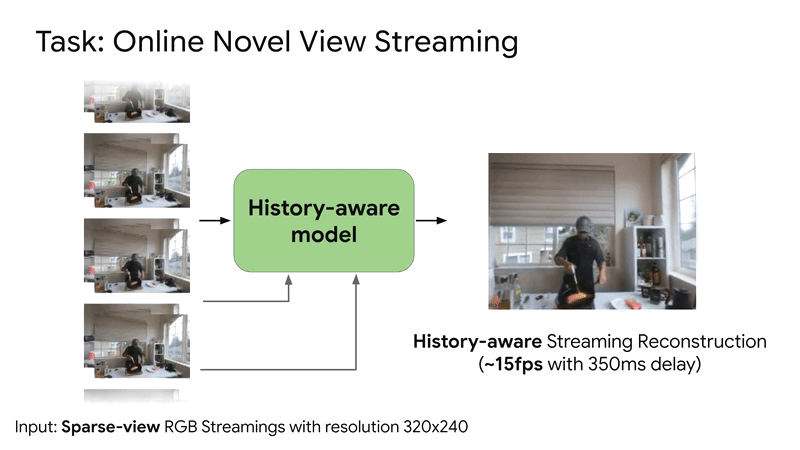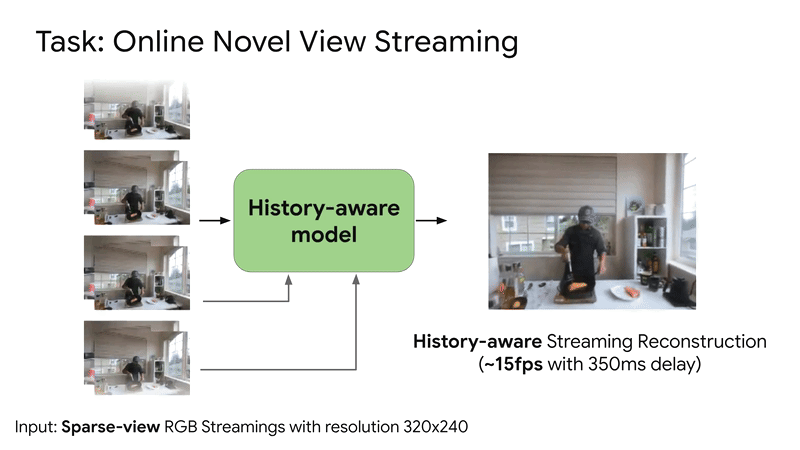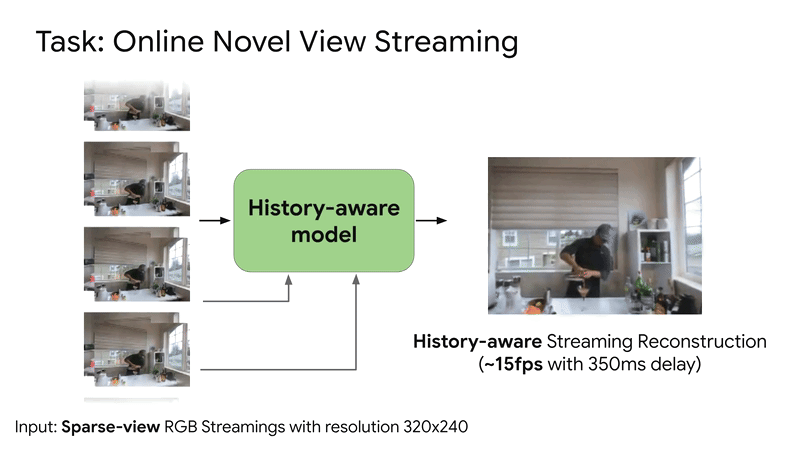
Authors: Yiming Wang, Lucy Chai, Xuan Luo, Michael Niemeyer, Manuel Lagunas, Stephen Lombardi, Siyu Tang, Tiancheng Sun
SplatVoxel is a hybrid Splat-Voxel representation that fuses and refines Gaussian Splatting, improving static scene reconstruction and enabling history-aware streaming reconstruction in a zero-shot manner.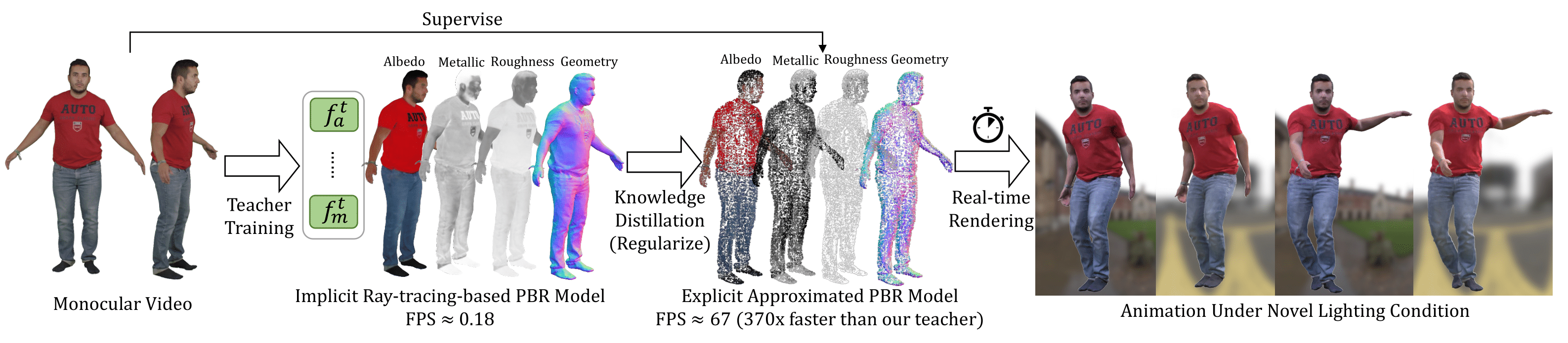
Authors: Zeren Jiang, Shaofei Wang, Siyu Tang
DNF-Avatar, a novel framework to distill knowledge from implicit model to explicit one for real-time rendering and relighting.
Authors: Yan Wu, Korrawe Karunratanakul, Zhengyi Luo, Siyu Tang
UniPhys is a diffusion-based unified planner and text-driven controller for physics-based character control. It generalizes across diverse tasks using a single model—from short-term reactive control tasks to long-term planning tasks, without requiring task-specific training.Multi-View 3D Point Tracking
Conference: International Conference on Computer Vision (ICCV 2025) oral presentation
Authors: Frano Rajič, Haofei Xu, Marko Mihajlovic, Siyuan Li, Irem Demir, Emircan Gündoğdu, Lei Ke, Sergey Prokudin, Marc Pollefeys, Siyu Tang
MVTracker is the first data-driven multi-view 3D point tracker.
Authors: Rui Wang, Quentin Lohmeyer, Mirko Meboldt, Siyu Tang
With gaussian splatting based self-supervised dynamic-static decomposition, DeGauss models SOTA distractor-free static scene from occluded inputs as casual captured images & challenging egocentric videos, and simultaneously yields high-quality & Efficient dynamic scene representation.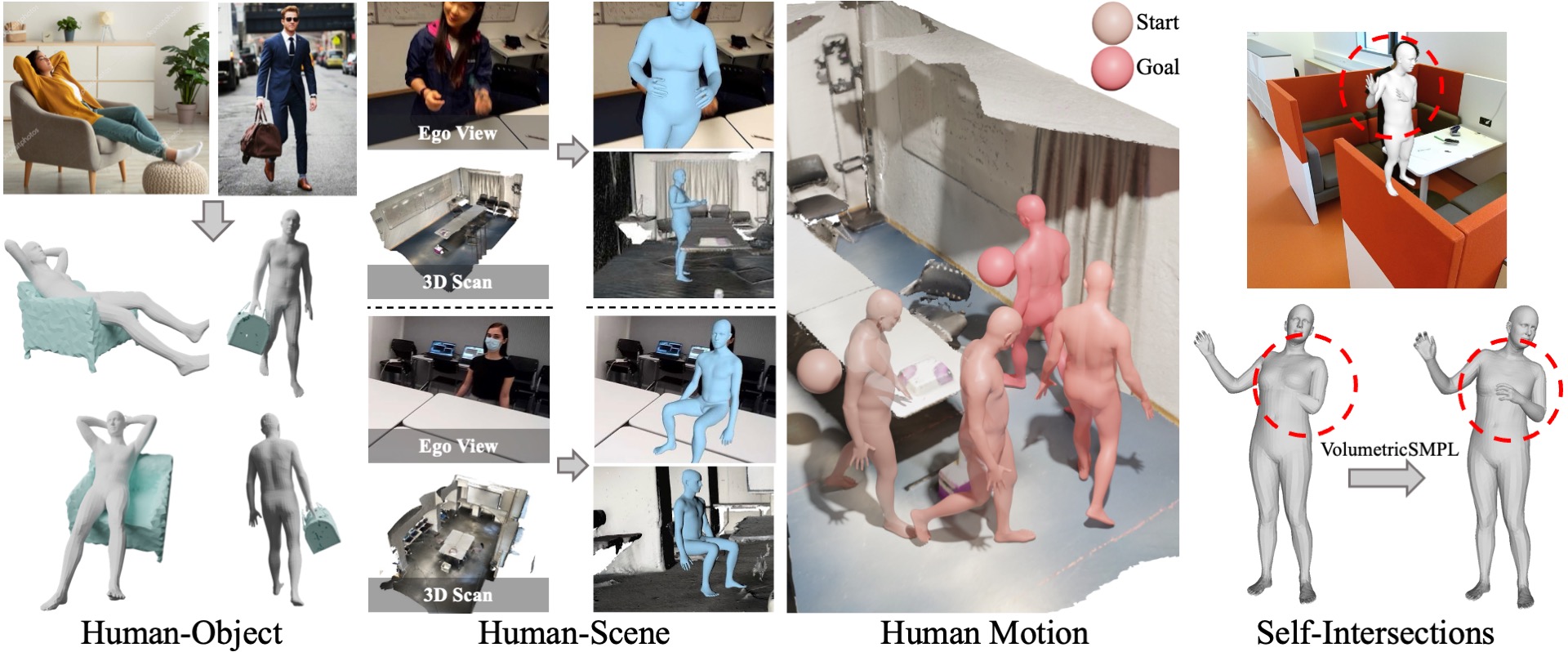
Authors: Marko Mihajlovic, Siwei Zhang, Gen Li, Kaifeng Zhao, Lea Müller, Siyu Tang
VolumetricSMPL is a lightweight extension that adds volumetric capabilities to SMPL(-X) models for efficient 3D interactions and collision detection.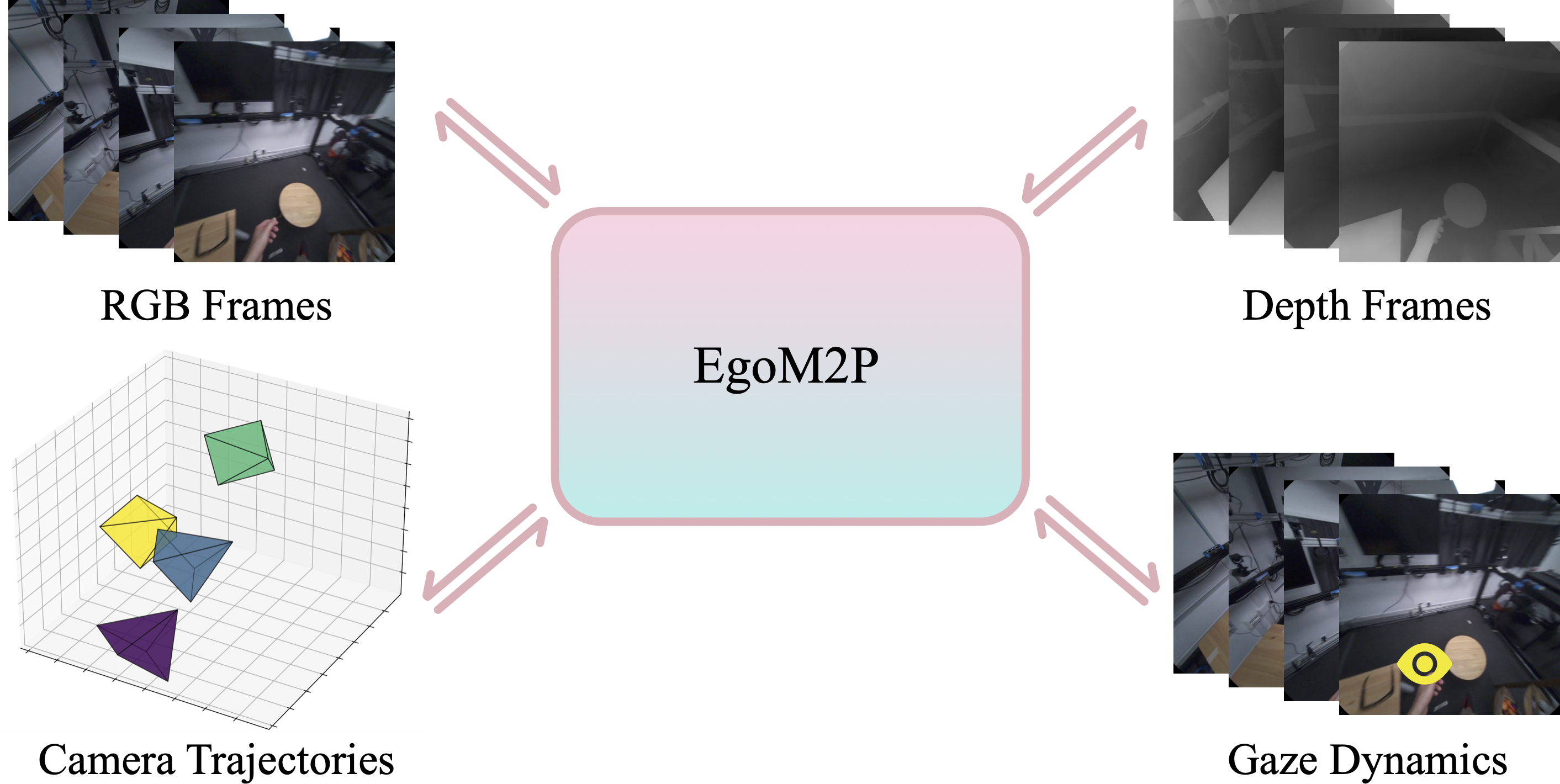
Authors: Gen Li, Yutong Chen*, Yiqian Wu*, Kaifeng Zhao*, Marc Pollefeys, Siyu Tang (*equal contribution)
EgoM2P: A large-scale egocentric multimodal and multitask model, pretrained on eight extensive egocentric datasets. It incorporates four modalities—RGB and depth video, gaze dynamics, and camera trajectories—to handle challenging tasks like monocular egocentric depth estimation, camera tracking, gaze estimation, and conditional egocentric video synthesis
Authors: Mingyang Song, Yang Zhang, Marko Mihajlovic, Siyu Tang, Markus Gross, Tunc Aydin
We combine splines, a classical tool from applied mathematics, with implicit Coordinate Neural Networks to model deformation fields, achieving strong performance across multiple datasets. The explicit regularization from spline interpolation enhances spatial coherency in challenging scenarios. We further introduce a metric based on Moran's I to quantitatively evaluate spatial coherence.
Authors: Zinuo You, Stamatios Georgoulis, Anpei Chen, Siyu Tang, Dengxin Dai
GaVS reformulates video stabilization task with feed-forward 3DGS reconstruction, ensuring robustness to diverse motions, full-frame rendering and high geometry consistency.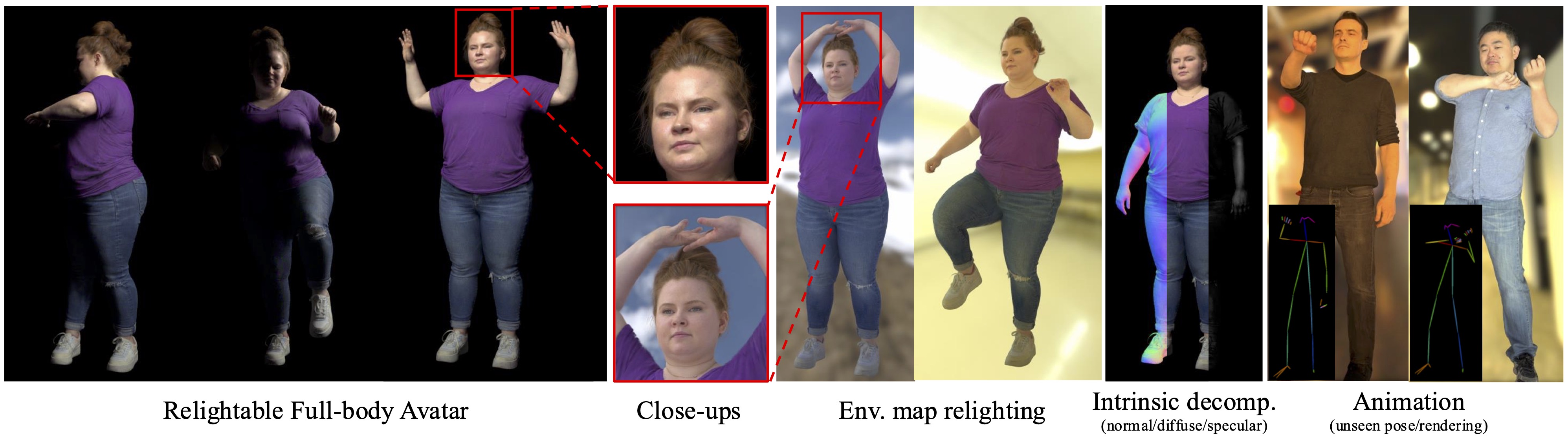
Authors: Shaofei Wang, Tomas Simon, Igor Santesteban, Timur Bagautdinov, Junxuan Li, Vasu Agrawal, Fabian Prada, Shoou-I Yu, Pace Nalbone, Matt Gramlich, Roman Lubachersky, Chenglei Wu, Javier Romero, Jason Saragih, Michael Zollhoefer, Andreas Geiger, Siyu Tang, Shunsuke Saito
RFGCA learns high-fidelity relightable and drivable full-body avatars from light stage captures.
Authors: Yiqian Wu, Malte Prinzler, Xiaogang Jin, Siyu Tang
AnimPortrait3D is a novel method for text-based, realistic, animatable 3DGS avatar generation with morphable model alignment.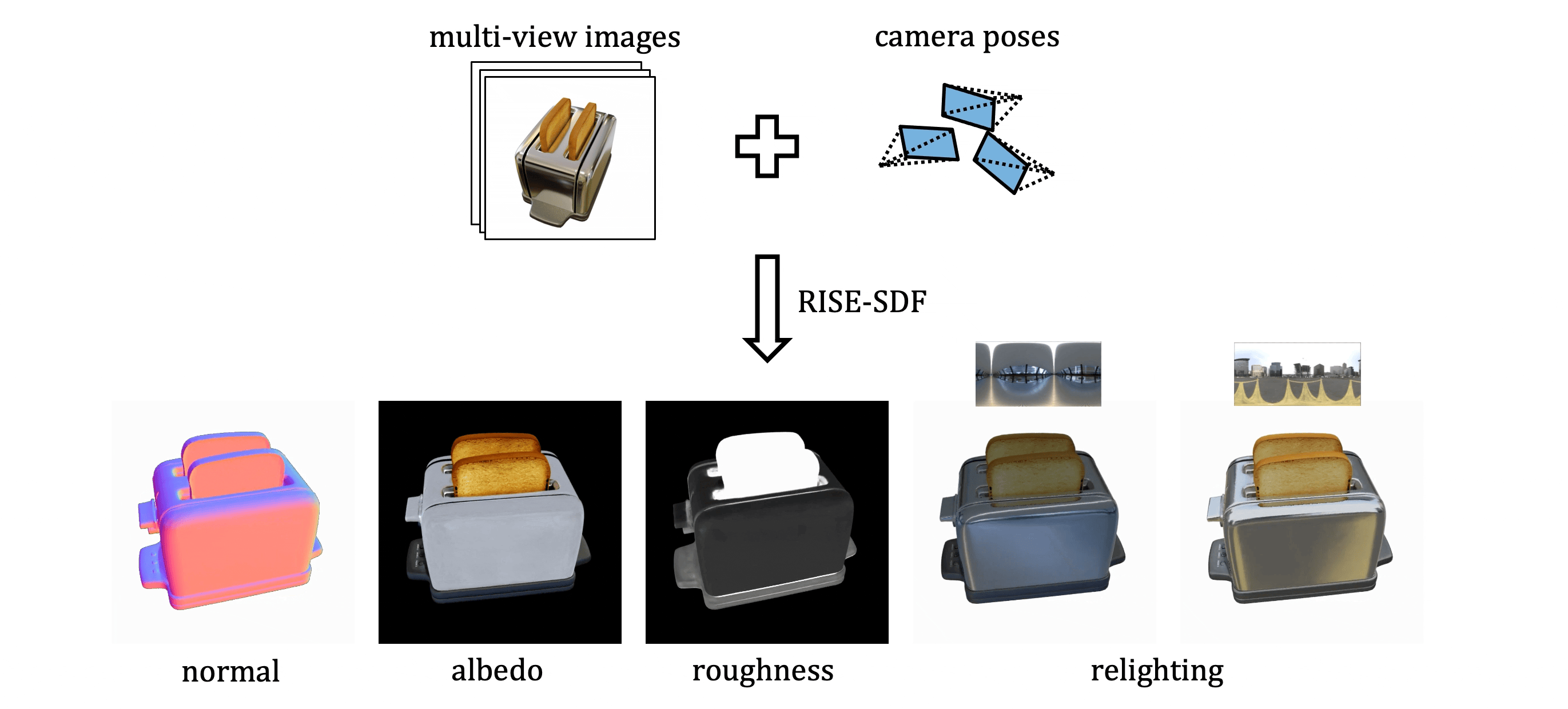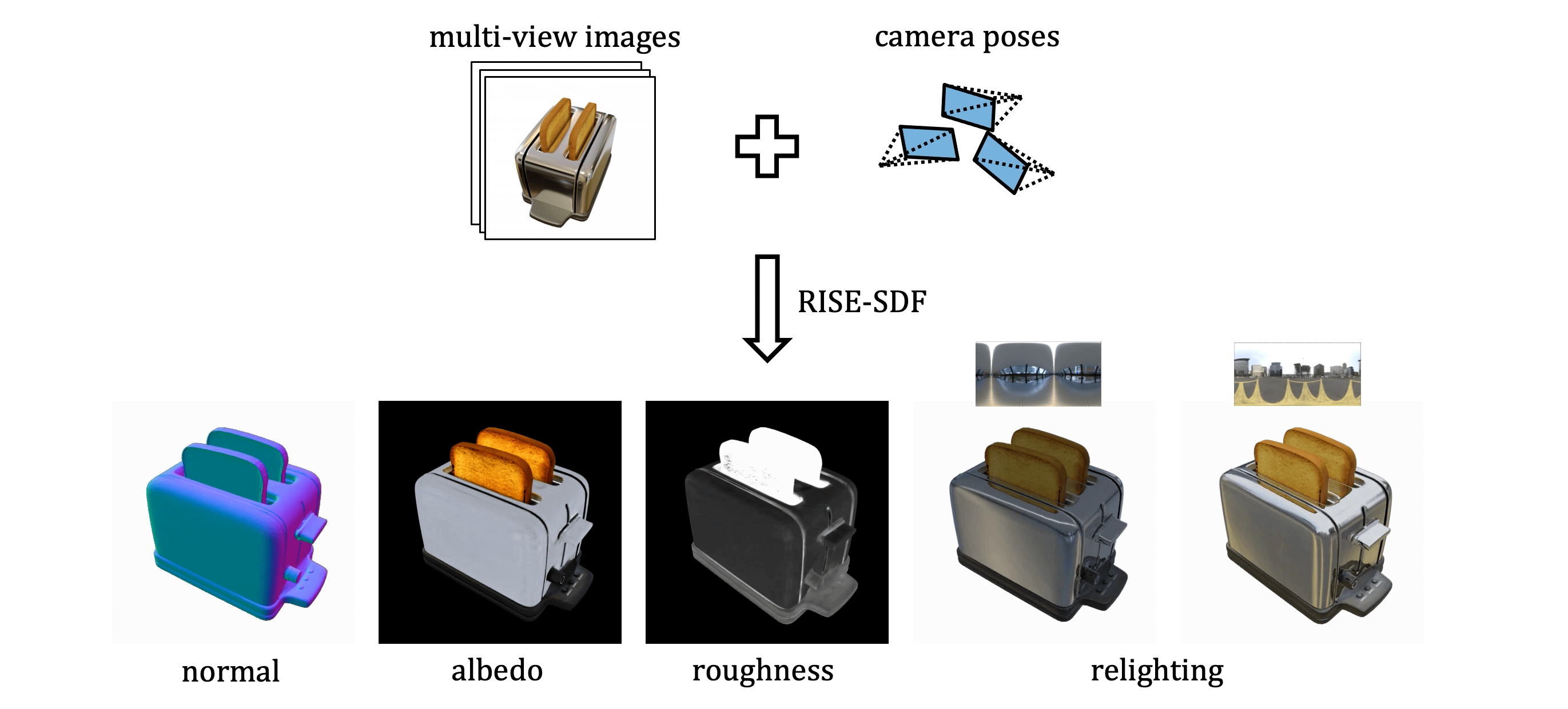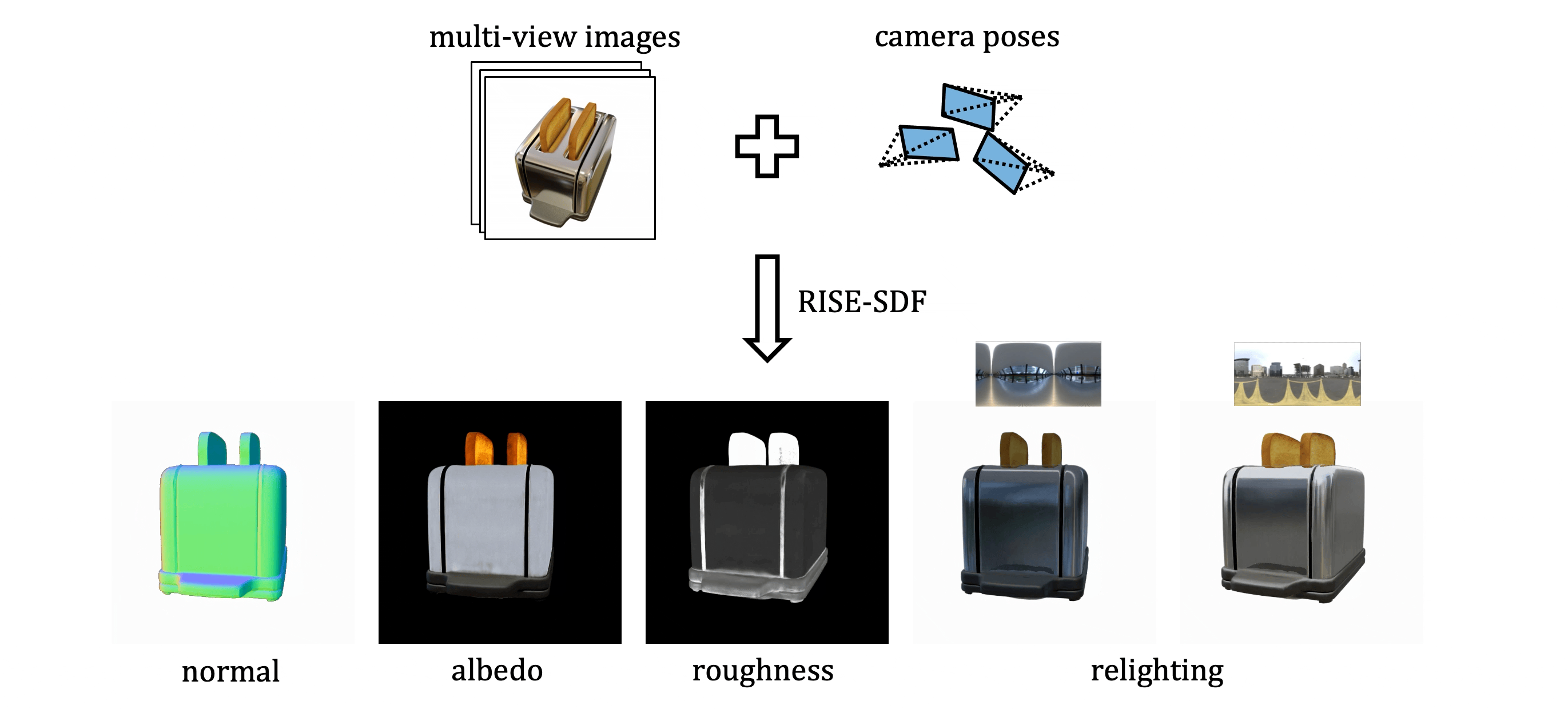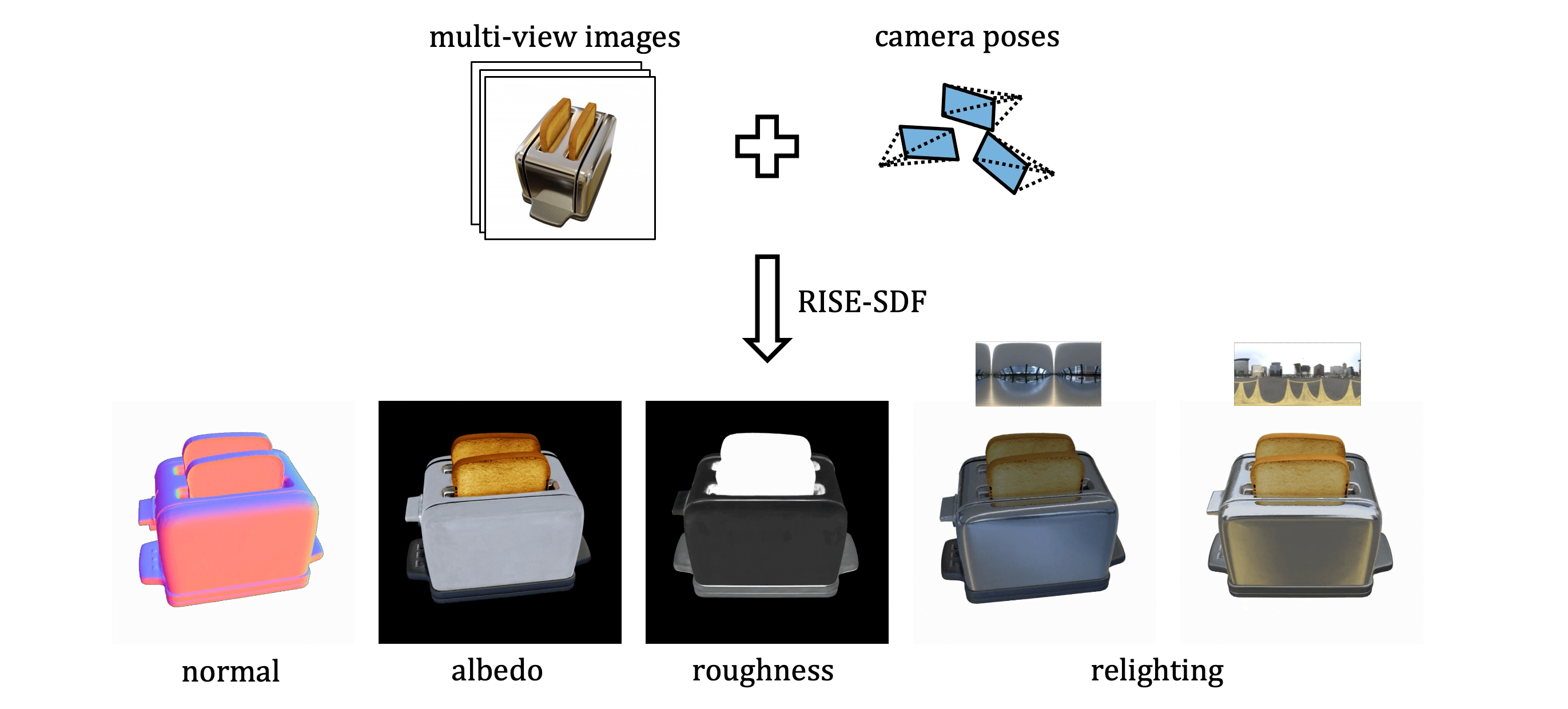
Authors: Deheng Zhang*, Jingyu Wang*, Shaofei Wang, Marko Mihajlovic, Sergey Prokudin, Hendrik P.A. Lensch, Siyu Tang (*equal contribution)
We present RISE-SDF, a method for reconstructing the geometry and material of glossy objects while achieving high-quality relighting.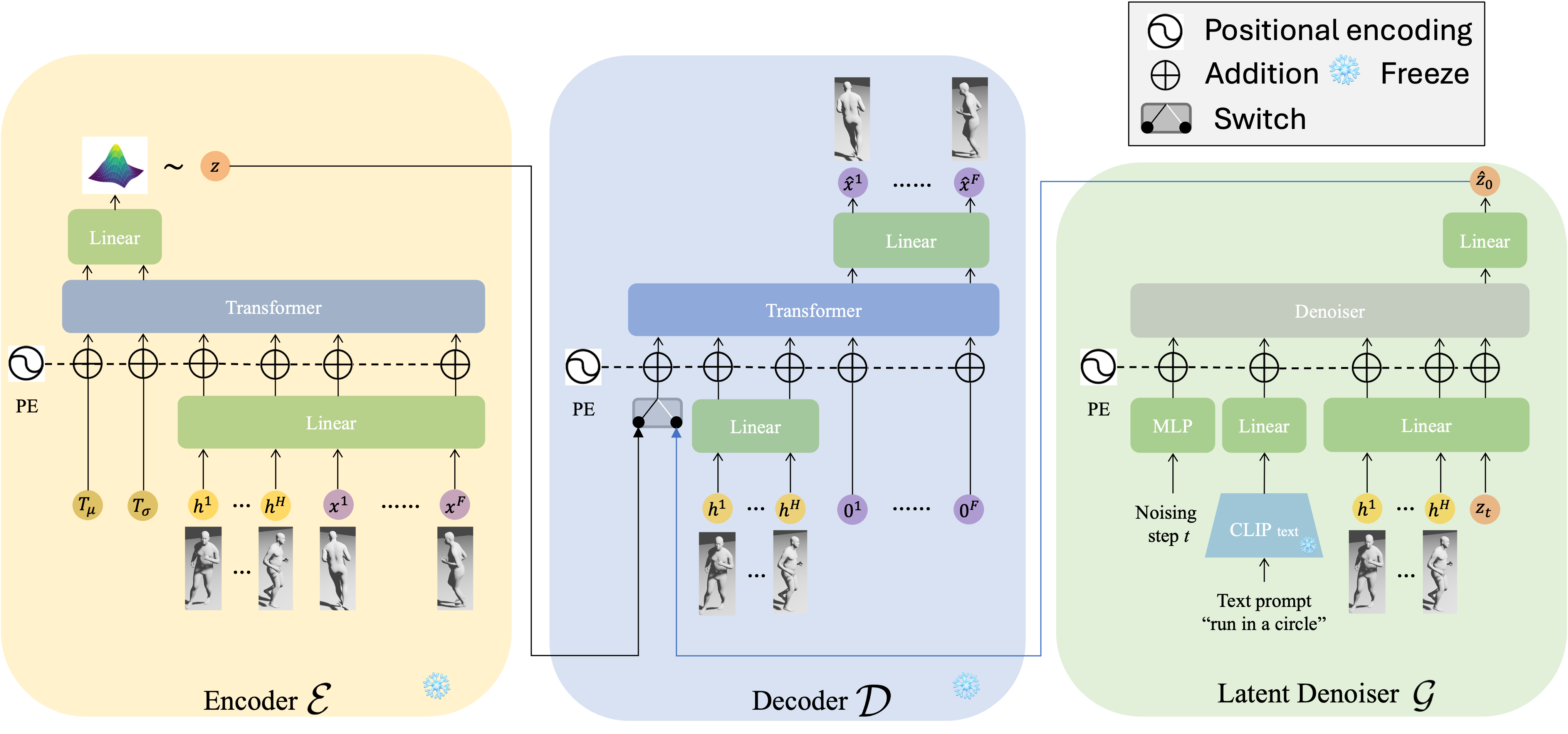
Authors: Kaifeng Zhao, Gen Li, Siyu Tang
DART is a Diffusion-based Autoregressive motion model for Real-time Text-driven motion control. Furthermore, DART enables various motion generation applications with spatial constraints and goals, including motion in-between, waypoint goal reaching, and human-scene interaction generation.
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
Conference: The Thirteenth International Conference on Learning Representations (ICLR 2025) spotlight presentation
Authors: Yutong Chen, Marko Mihajlovic, Xiyi Chen, Yiming Wang, Sergey Prokudin, Siyu Tang
We analyze the performance of novel view synthesis methods in challenging out-of-distribution (OOD) camera views and introduce SplatFormer, a data-driven 3D transformer designed to refine 3D Gaussian splatting primitives for improved quality in extreme camera scenarios.2024

Authors: Marko Mihajlovic, Sergey Prokudin, Siyu Tang, Robert Maier, Federica Bogo, Tony Tung, Edmond Boyer
SplatFields regularizes 3D gaussian splats for sparse 3D and 4D reconstruction.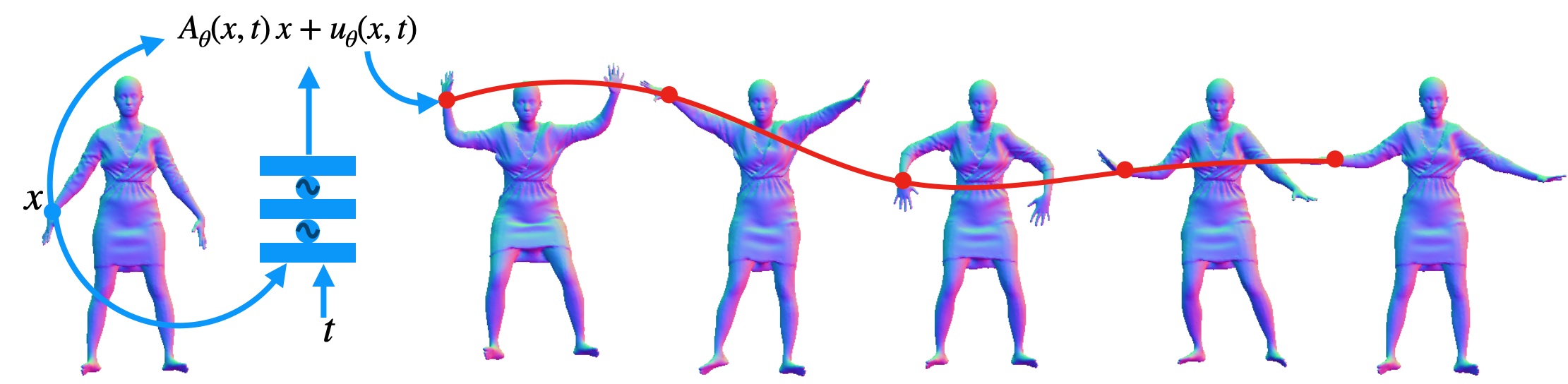
Authors: Yan Zhang, Sergey Prokudin, Marko Mihajlovic, Qianli Ma, Siyu Tang
DOMA is an implicit motion field modeled by a spatiotemporal SIREN network. The learned motion field can predict how novel points move in the same field.
Authors: Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, Siyu Tang
Diffusion Noise Optimization (DNO) can leverage the existing human motion diffusion models as universal motion priors. We demonstrate its capability in the motion editing tasks where DNO can preserve the content of the original model and accommodates a diverse range of editing modes, including changing trajectory, pose, joint location, and avoiding newly added obstacles.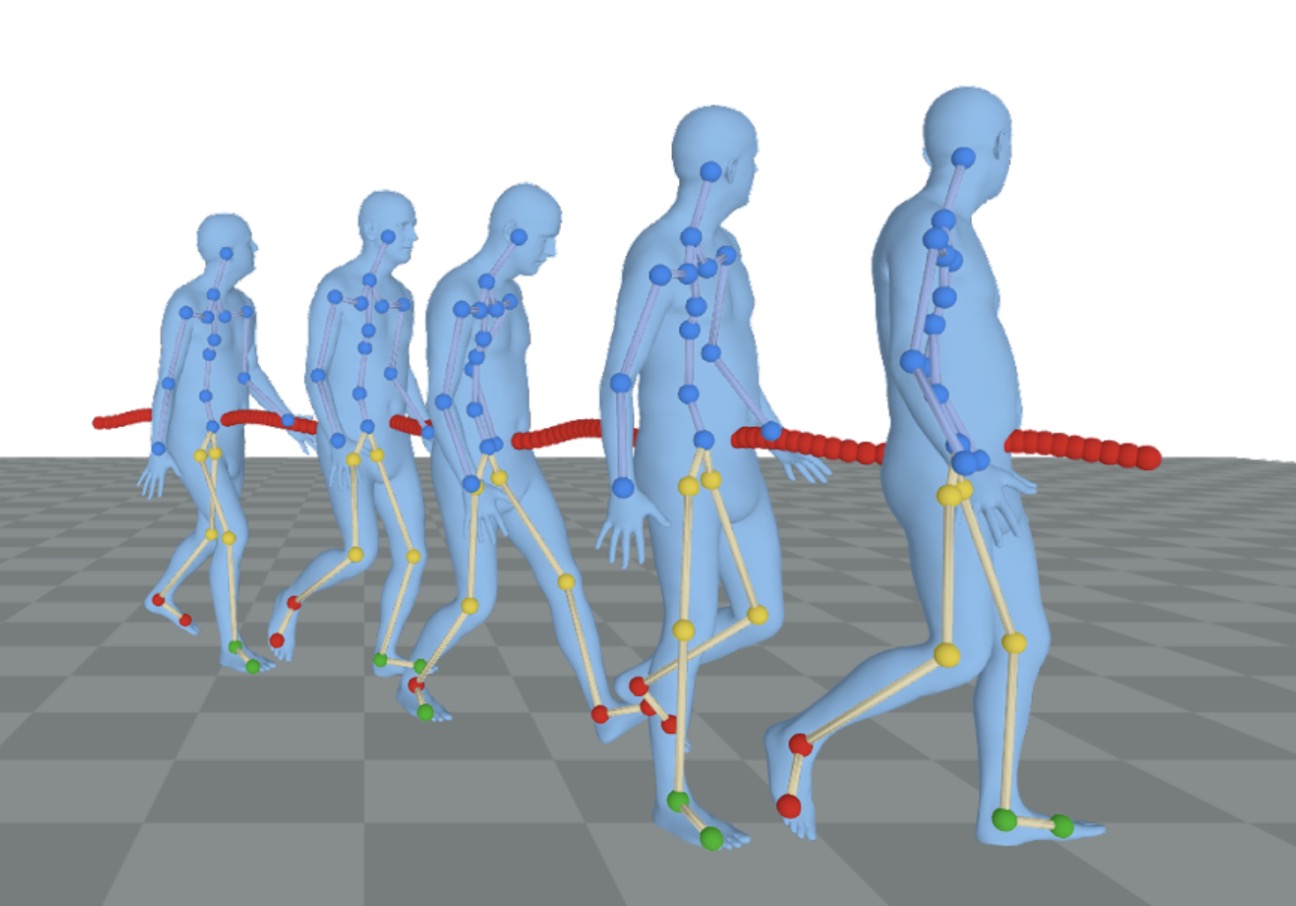
RoHM: Robust Human Motion Reconstruction via Diffusion
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2024) oral presentation
Authors: Siwei Zhang, Bharat Lal Bhatnagar, Yuanlu Xu, Alexander Winkler, Petr Kadlecek, Siyu Tang, Federica Bogo
Conditioned on noisy and occluded input data, RoHM reconstructs complete, plausible motions in consistent global coordinates.
EgoGen: An Egocentric Synthetic Data Generator
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2024) oral presentation
Authors: Gen Li, Kaifeng Zhao, Siwei Zhang, Xiaozhong Lyu, Mihai Dusmanu, Yan Zhang, Marc Pollefeys, Siyu Tang
EgoGen is new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks.
Authors: Shaofei Wang , Božidar Antić , Andreas Geiger , Siyu Tang
IntrinsicAvatar learns relightable and animatable avatars from monocular videos, without any data-driven priors.
Authors: Xiyi Chen , Marko Mihajlovic , Shaofei Wang , Sergey Prokudin , Siyu Tang
We introduce a morphable diffusion model to enable consistent controllable novel view synthesis of humans from a single image. Given a single input image and a morphable mesh with a desired facial expression, our method directly generates 3D consistent and photo-realistic images from novel viewpoints, which we could use to reconstruct a coarse 3D model using off-the-shelf neural surface reconstruction methods such as NeuS2.Authors: Zhiyin Qian, Shaofei Wang, Marko Mihajlovic, Andreas Geiger, Siyu Tang
Given a monocular video, 3DGS-Avatar learns clothed human avatars that model pose-dependent appearance and generalize to out-of-distribution poses, with short training time and interactive rendering frame rate.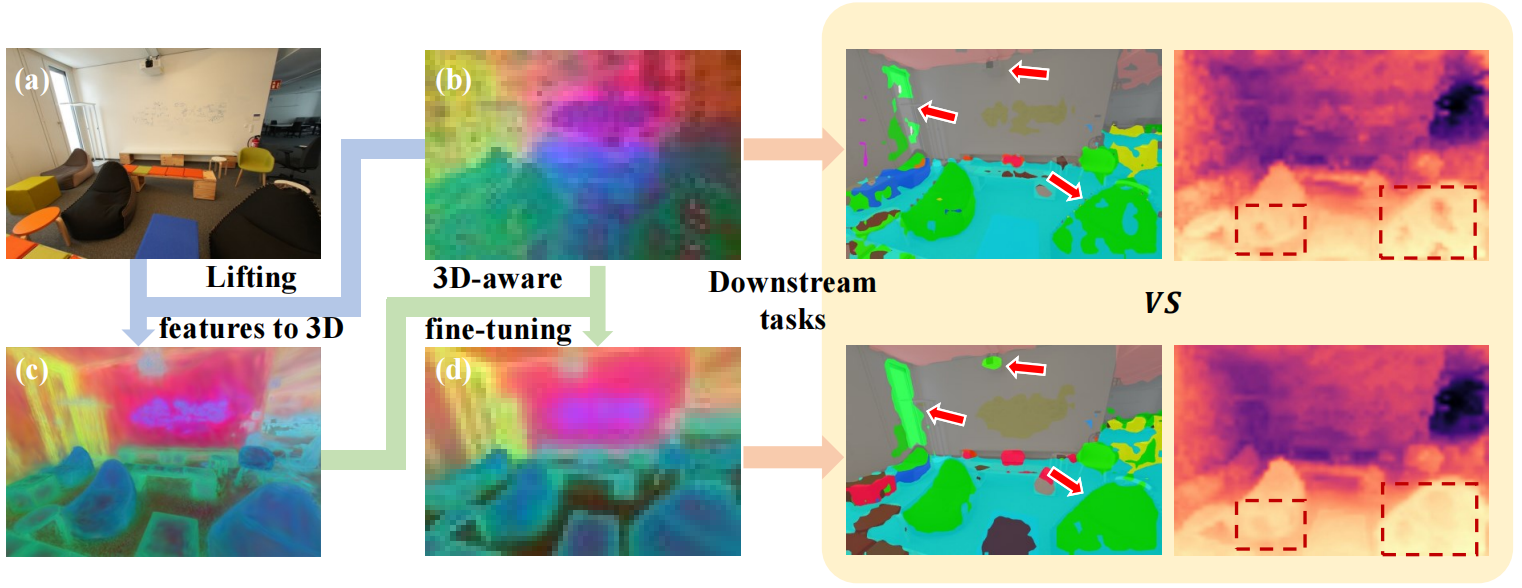
Authors: Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, Jan Eric Lenssen
We propose 3D-aware fine-tuning to improve 2D foundation features.
Authors: Anpei Chen, Haofei Xu, Stefano Esposito, Siyu Tang, Andreas Geiger
We train a feed-forward 2DGS model in two days using 4 GPUs.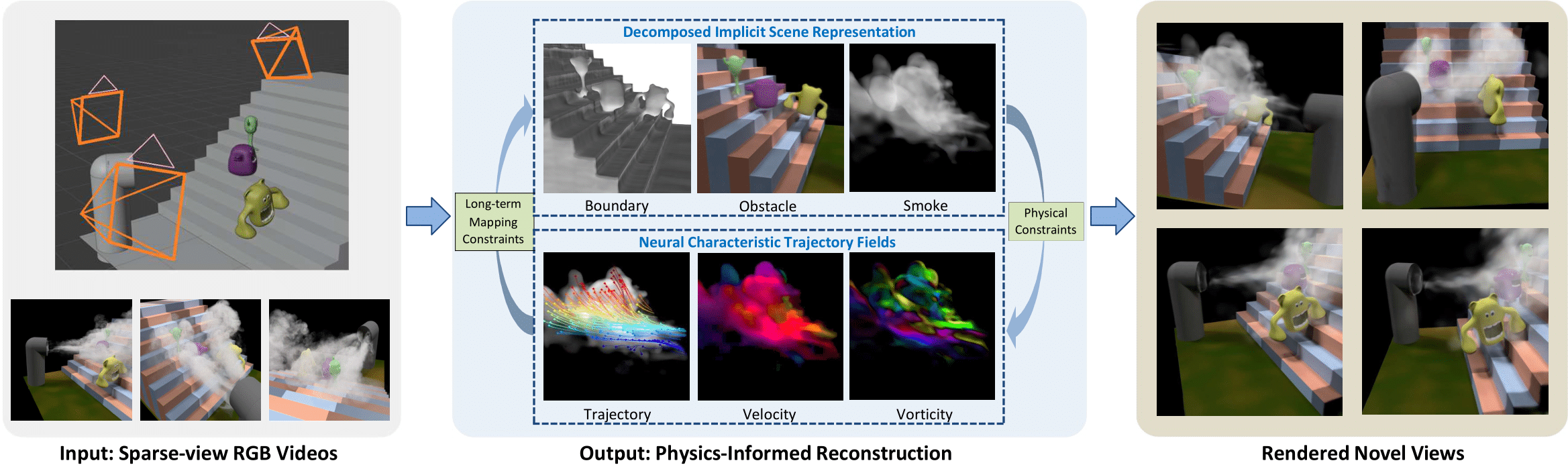
Authors: Yiming Wang, Siyu Tang, Mengyu Chu
We introduce Neural Characteristic Trajectory Fields, a novel representation utilizing Eulerian neural fields to implicitly model Lagrangian fluid trajectories.
Authors: Yiqian Wu, Hao Xu, Xiangjun Tang, Xien Chen, Siyu Tang, Zhebin Zhang, Chen Li, Xiaogang Jin
Portrait3D is a novel neural rendering-based framework with a novel joint geometry-appearance prior to achieve high-quality text-to-3D-portrait generation.
ResFields: Residual Neural Fields for Spatiotemporal Signals
Conference: International Conference on Learning Representations (ICLR 2024) spotlight presentation
Authors: Marko Mihajlovic, Sergey Prokudin, Marc Pollefeys, Siyu Tang
ResField layers incorporates time-dependent weights into MLPs to effectively represent complex temporal signals.2023
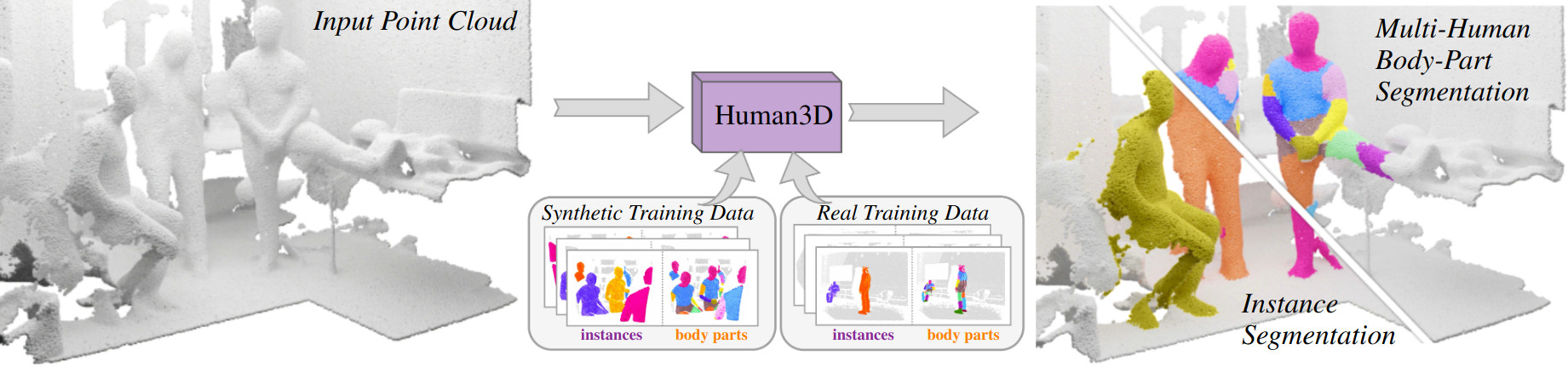
Authors: Ayça Takmaz*, Jonas Schult*, Irem Kaftan, Mertcan Akçay, Bastian Leibe, Robert Sumner, Francis Engelmann, Siyu Tang
We propose the first multi-human body-part segmentation model, called Human3D 🧑🤝🧑, that directly operates on 3D scenes. In an extensive analysis, we validate the benefits of training on synthetic data on multiple baselines and tasks.
Authors: Kaifeng Zhao, Yan Zhang, Shaofei Wang, Thabo Beeler, Siyu Tang
Interaction with environments is one core ability of virtual humans and remains a challenging problem. We propose a method capable of generating a sequence of natural interaction events in real cluttered scenes.
Authors: Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, Siyu Tang
Guided Motion Diffusion (GMD) model can synthesize realistic human motion according to a text prompt, a reference trajectory, and key locations, as well as avoiding hitting your toe on giant X-mark circles that someone dropped on the floor. No need to retrain diffusion models for each of these tasks!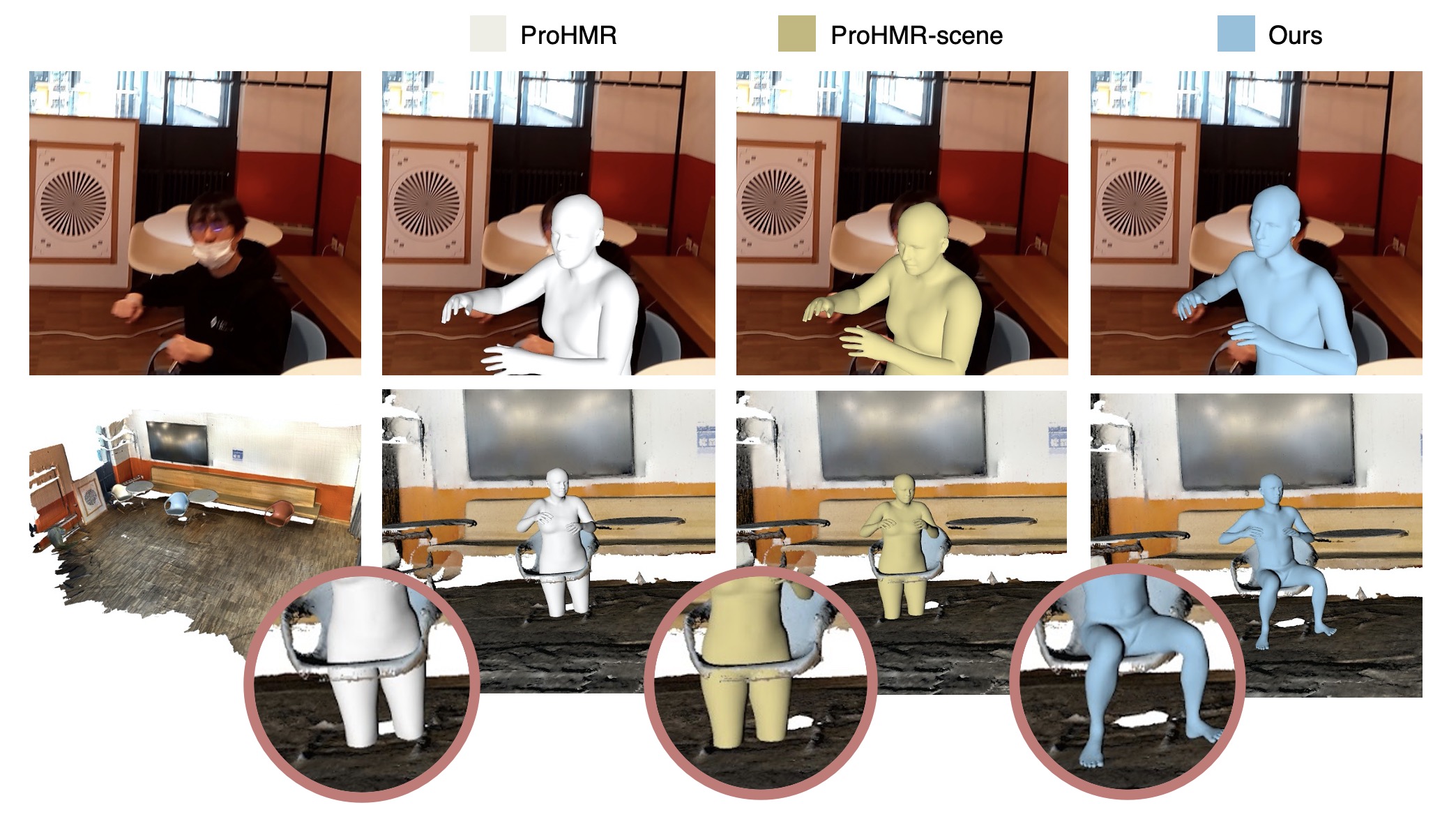
Authors: Siwei Zhang, Qianli Ma, Yan Zhang, Sadegh Aliakbarian, Darren Cosker, Siyu Tang
We propose a novel scene-conditioned probabilistic method to recover the human mesh from an egocentric view image (typically with the body truncated) in the 3D environment.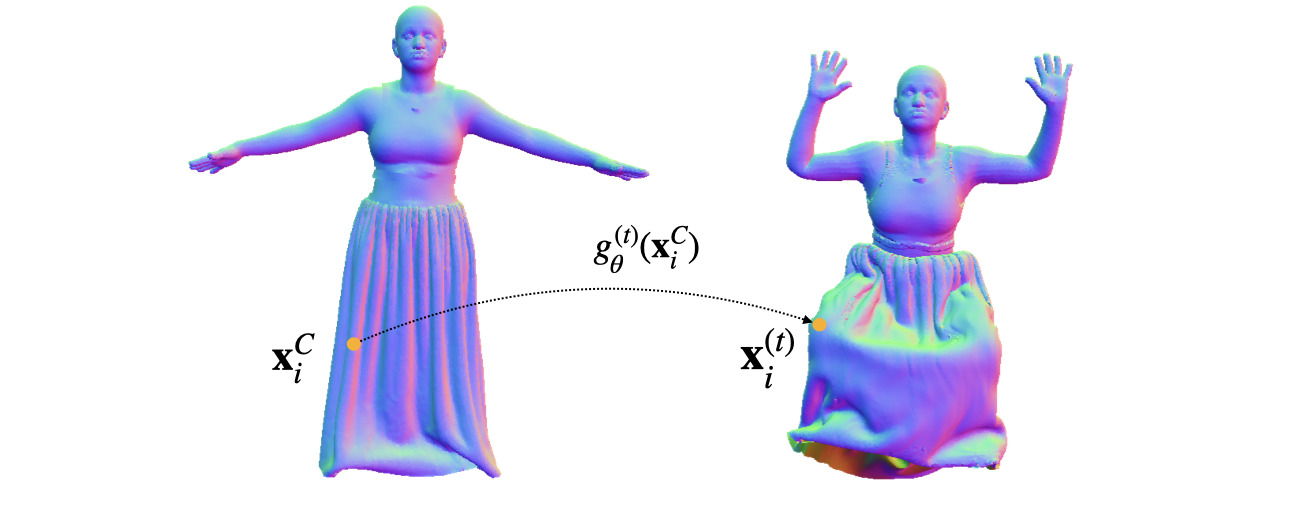
Authors: Sergey Prokudin, Qianli Ma, Maxime Raafat, Julien Valentin, Siyu Tang
We propose to model dynamic surfaces with a point-based model, where the motion of a point over time is represented by an implicit deformation field. Working directly with points (rather than SDFs) allows us to easily incorporate various well-known deformation constraints, e.g. as-isometric-as-possible. We showcase the usefulness of this approach for creating animatable avatars in complex clothing.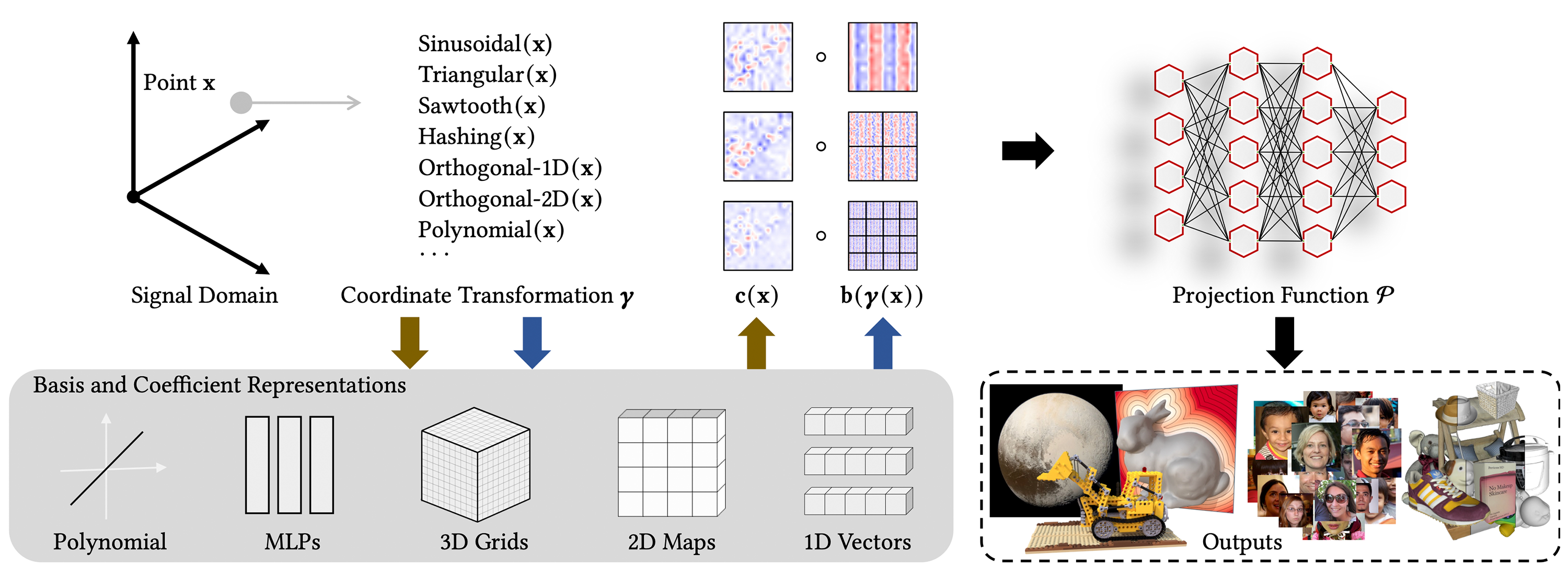
Authors: Anpei Chen, Zexiang Xu, Xinyue Wei, Siyu Tang, Hao Su, Andreas Geiger
We present Dictionary Fields, a novel neural representation which decomposes a signal into a product of factors, each represented by a classical or neural field representation, operating on transformed input coordinates.
Interactive Object Segmentation in 3D Point Clouds
Conference: International Conference on Robotics and Automation (ICRA 2023) Best Paper Nominee
Authors: Theodora Kontogianni, Ekin Celikkan, Siyu Tang, Konrad Schindler
We present interactive object segmentation directly in 3D point clouds. Users provide feedback to a deep learning model in the form of positive and negative clicks to segment a 3D object of interest.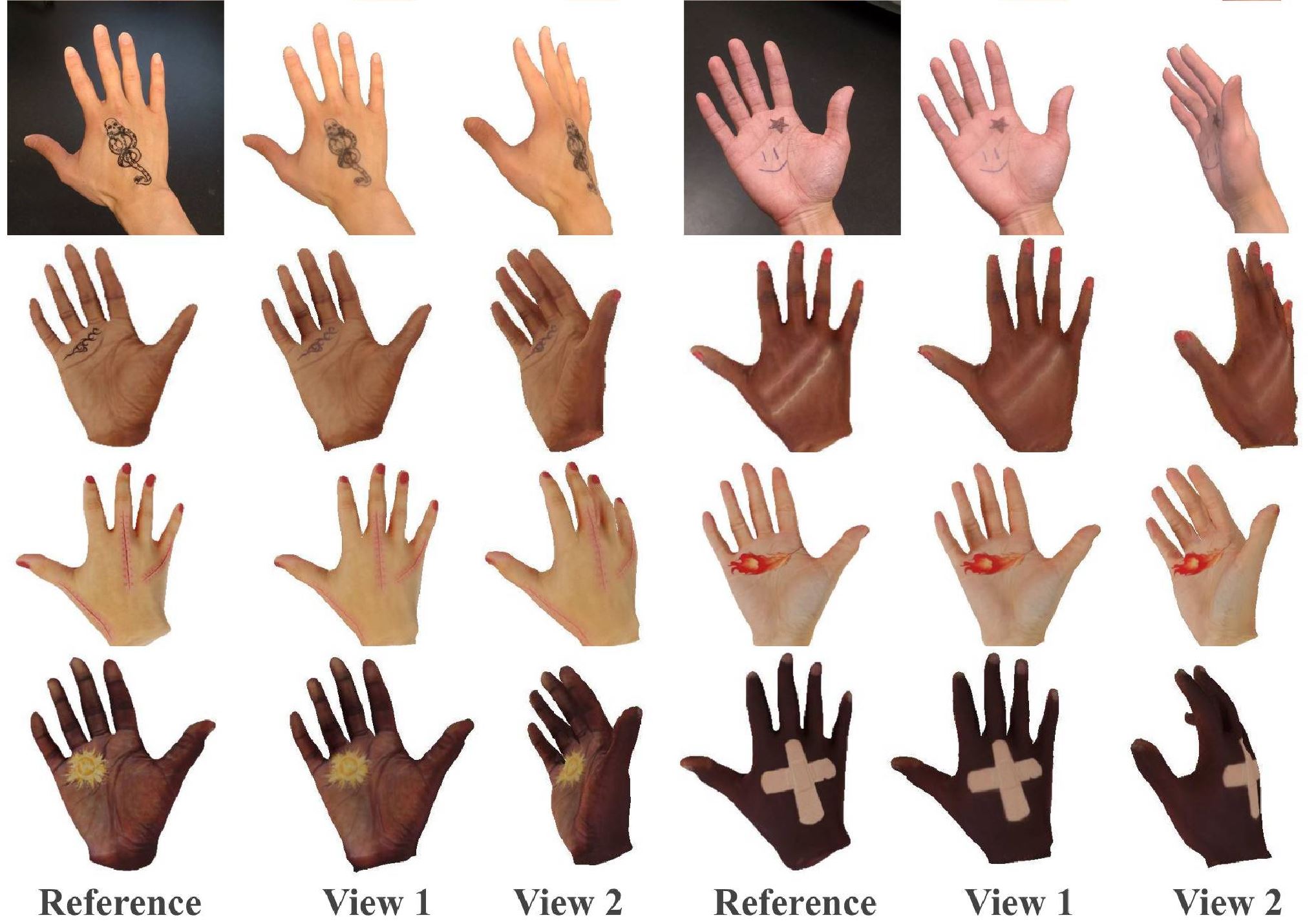
Authors: Korrawe Karunratanakul, Sergey Prokudin, Otmar Hilliges, Siyu Tang
We present HARP (HAnd Reconstruction and Personalization), a personalized hand avatar creation approach that takes a short monocular RGB video of a human hand as input and reconstructs a faithful hand avatar exhibiting a high-fidelity appearance and geometry.
Authors: Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe
Mask3D predicts accurate 3D semantic instances achieving state-of-the-art on ScanNet, ScanNet200, S3DIS and STPLS3D.2022

Authors: Qianli Ma, Jinlong Yang, Michael J. Black and Siyu Tang
The power of point-based digital human representations further unleashed: SkiRT models dynamic shapes of 3D clothed humans including those that wear challenging outfits such as skirts and dresses.
Authors: Siwei Zhang, Qianli Ma, Yan Zhang, Zhiyin Qian, Taein Kwon, Marc Pollefeys, Federica Bogo and Siyu Tang
A large-scale dataset of accurate 3D human body shape, pose and motion of humans interacting in 3D scenes, with multi-modal streams from third-person and egocentric views, captured by Azure Kinects and a HoloLens2.
Authors: Marko Mihajlovic, Aayush Bansal, Michael Zollhoefer, Siyu Tang, Shunsuke Saito
KeypointNeRF is a generalizable neural radiance field for virtual avatars.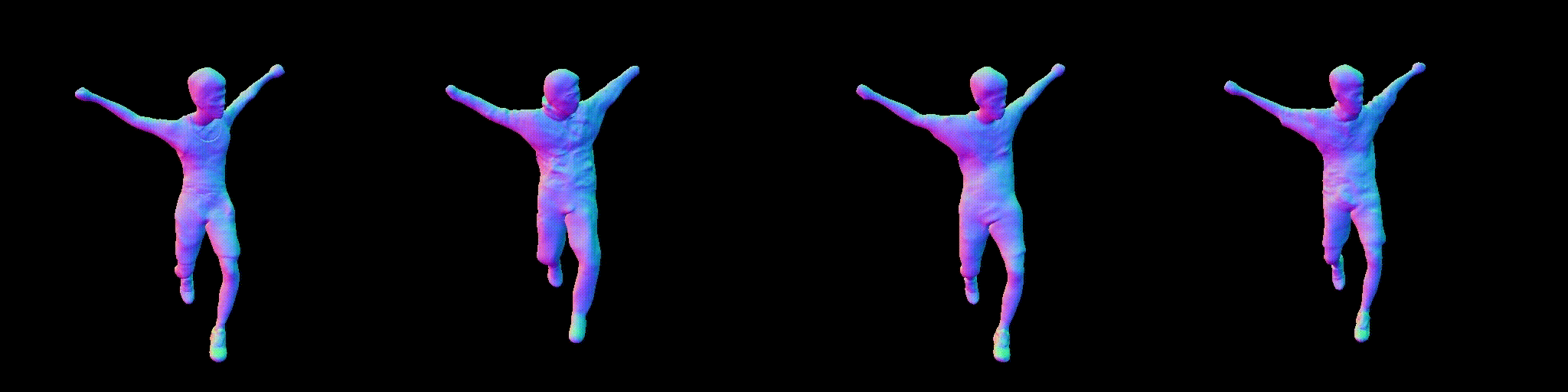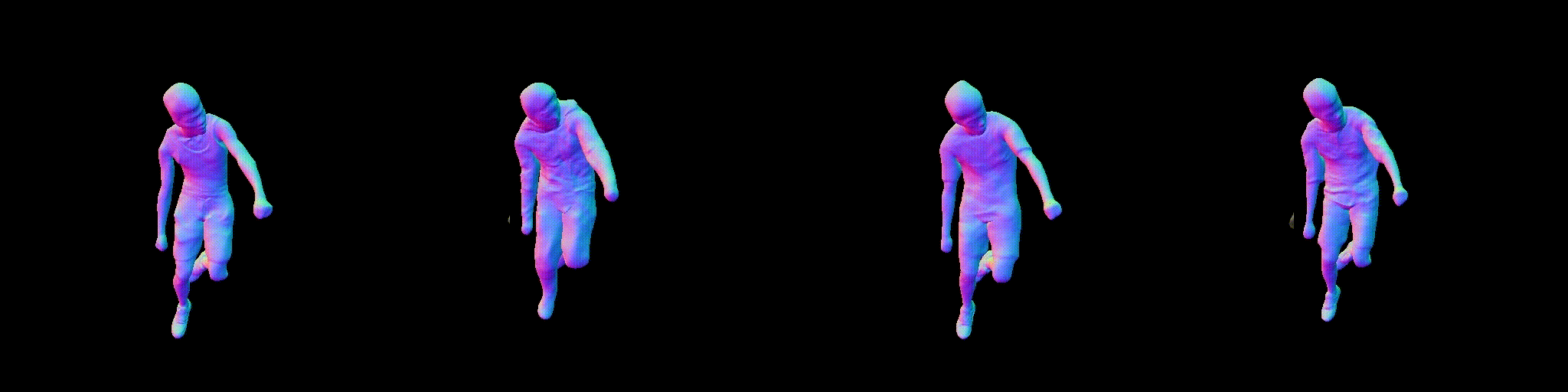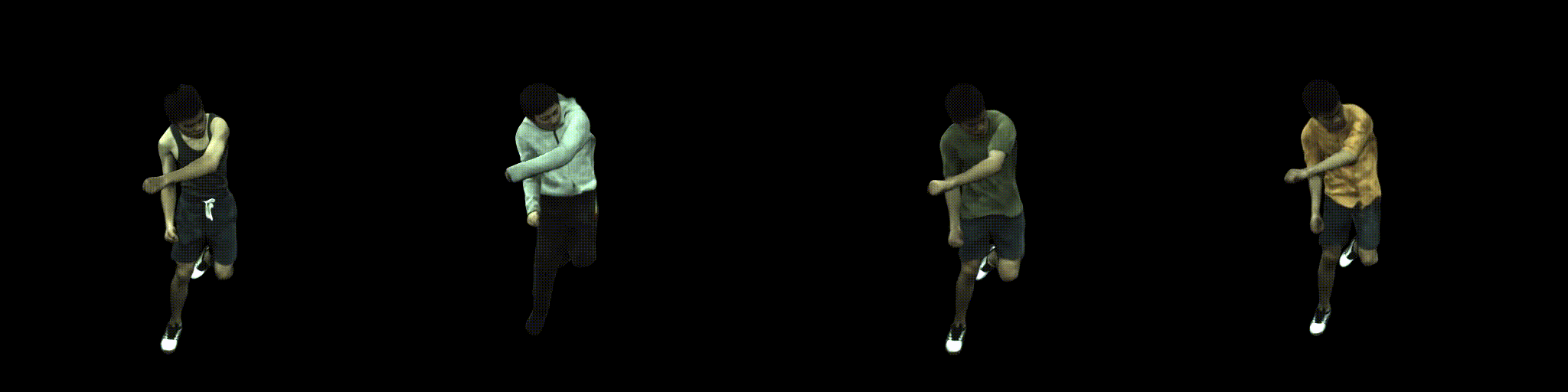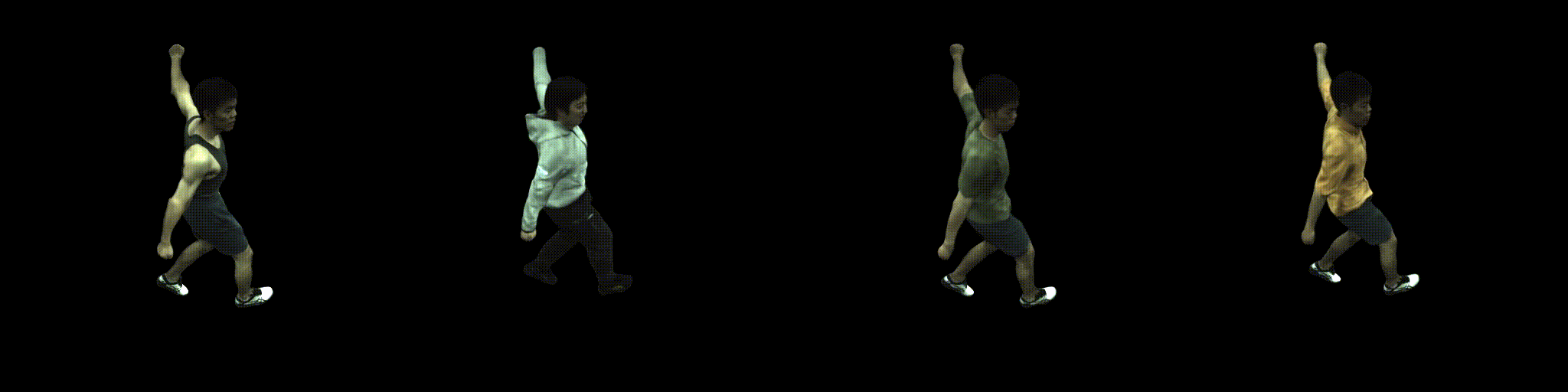
Authors: Shaofei Wang, Katja Schwarz, Andreas Geiger, Siyu Tang
Given sparse multi-view videos, ARAH learns animatable clothed human avatars that have detailed pose-dependent geometry/appearance and generalize to out-of-distribution poses.
Authors: Kaifeng Zhao, Shaofei Wang, Yan Zhang, Thabo Beeler, Siyu Tang
Synthesizing natural interactions between virtual humans and their 3D environments is critical for numerous applications, such as computer games and AR/VR experiences. We propose COINS, for COmpositional INteraction Synthesis with Semantic Control.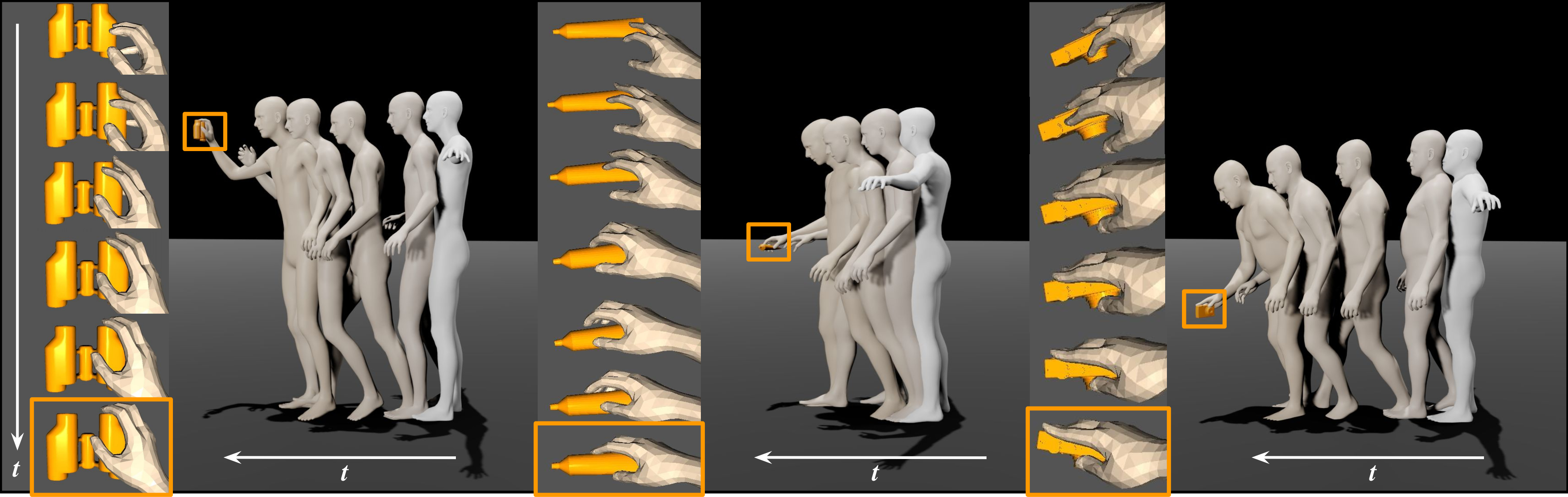
Authors: Yan Wu*, Jiahao Wang*, Yan Zhang, Siwei Zhang, Otmar Hilliges, Fisher Yu and Siyu Tang
(* denotes equal contribution)
Authors: Marko Mihajlovic , Shunsuke Saito , Aayush Bansal , Michael Zollhoefer and Siyu Tang
COAP is a novel neural implicit representation for articulated human bodies that provides an efficient mechanism for modeling self-contacts and interactions with 3D environments.
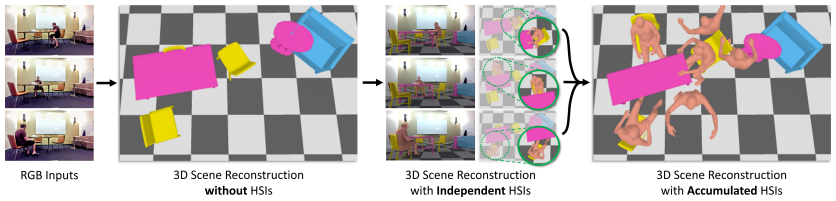
Authors: Hongwei Yi, Chun-Hao Paul Huang, Dimitrios Tzionas, Muhammed Kocabas, Mohamed Hassan, Siyu Tang, Justus Thies, Michael Black
Humans are in constant contact with the world as they move through it and interact with it. This contact is a vital source of information for understanding 3D humans, 3D scenes, and the interactions between them.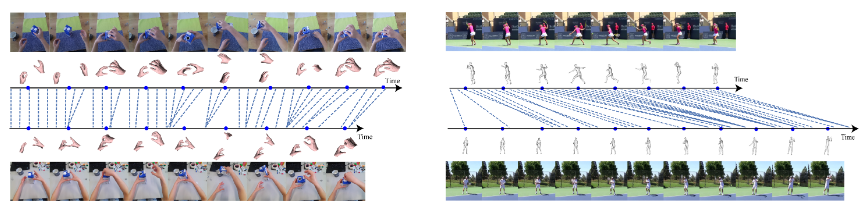
Authors: Taein Kwon, Bugra Tekin, Siyu Tang, Marc Pollefeys
Temporal alignment of fine-grained human actions in videos is important for numerous applications in computer vision, robotics, and mixed reality.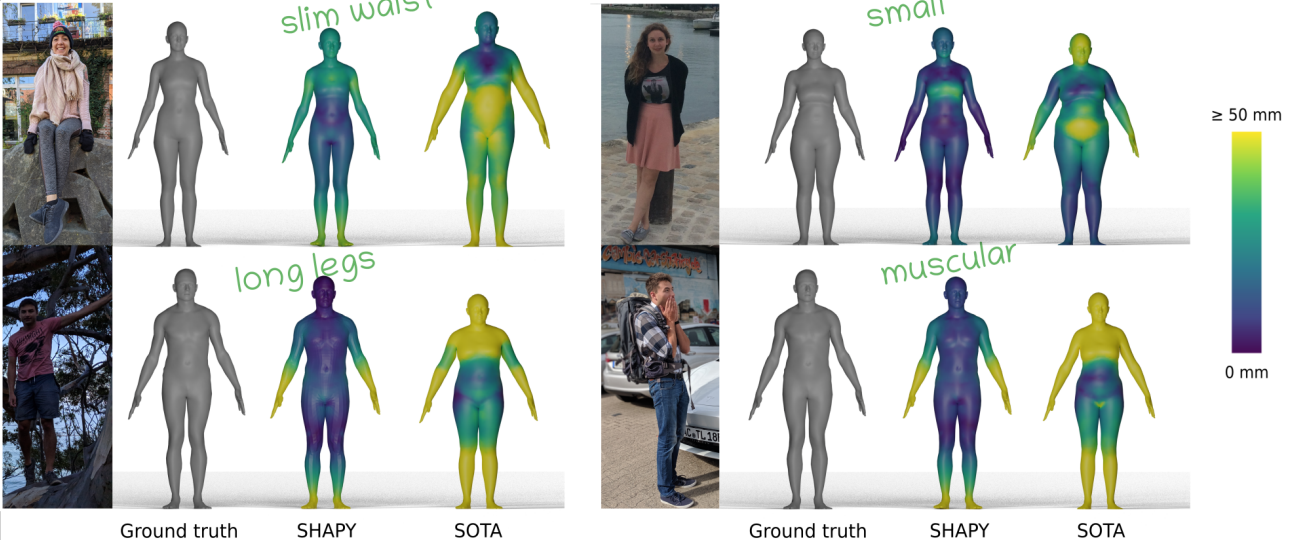
Accurate 3D Body Shape Regression using Metric and Semantic Attributes
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2022) oral presentation & best paper finalist
Authors: Vassilis Choutas, Lea Müller, Chun-Hao Paul Huang, Siyu Tang, Dimitrios Tzionas, Michael Black
We exploit the anthropometric measurements and linguistic shape attributes in several novel ways to train a neural network, called SHAPY, that regresses 3D human pose and shape from an RGB image.2021
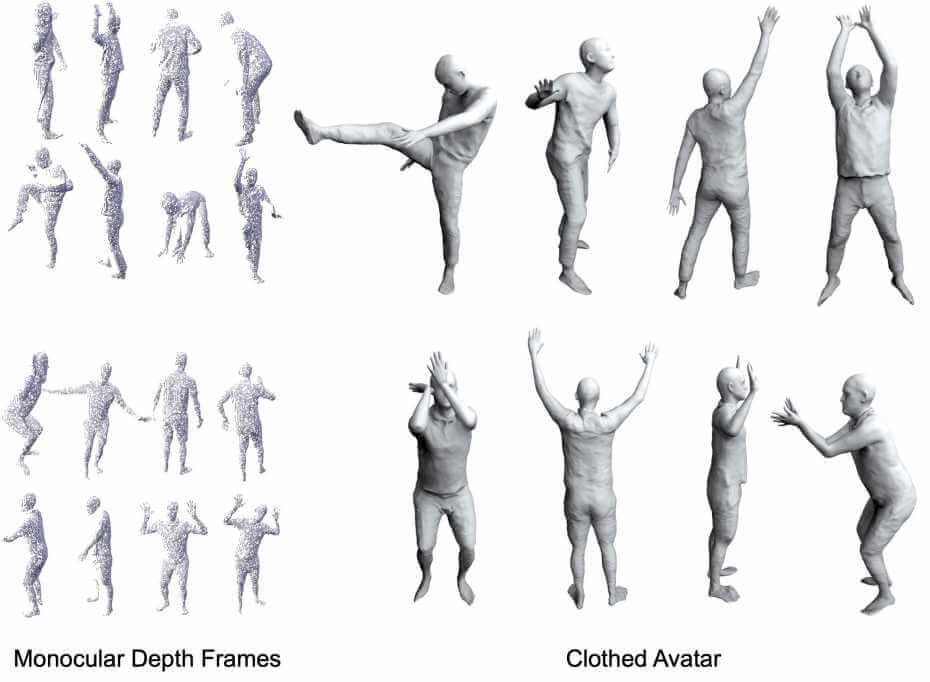
Authors: Shaofei Wang, Marko Mihajlovic, Qianli Ma, Andreas Geiger, Siyu Tang
MetaAvatar is meta-learned model that represents generalizable and controllable neural signed distance fields (SDFs) for clothed humans. It can be fast fine-tuned to represent unseen subjects given as few as 8 monocular depth images.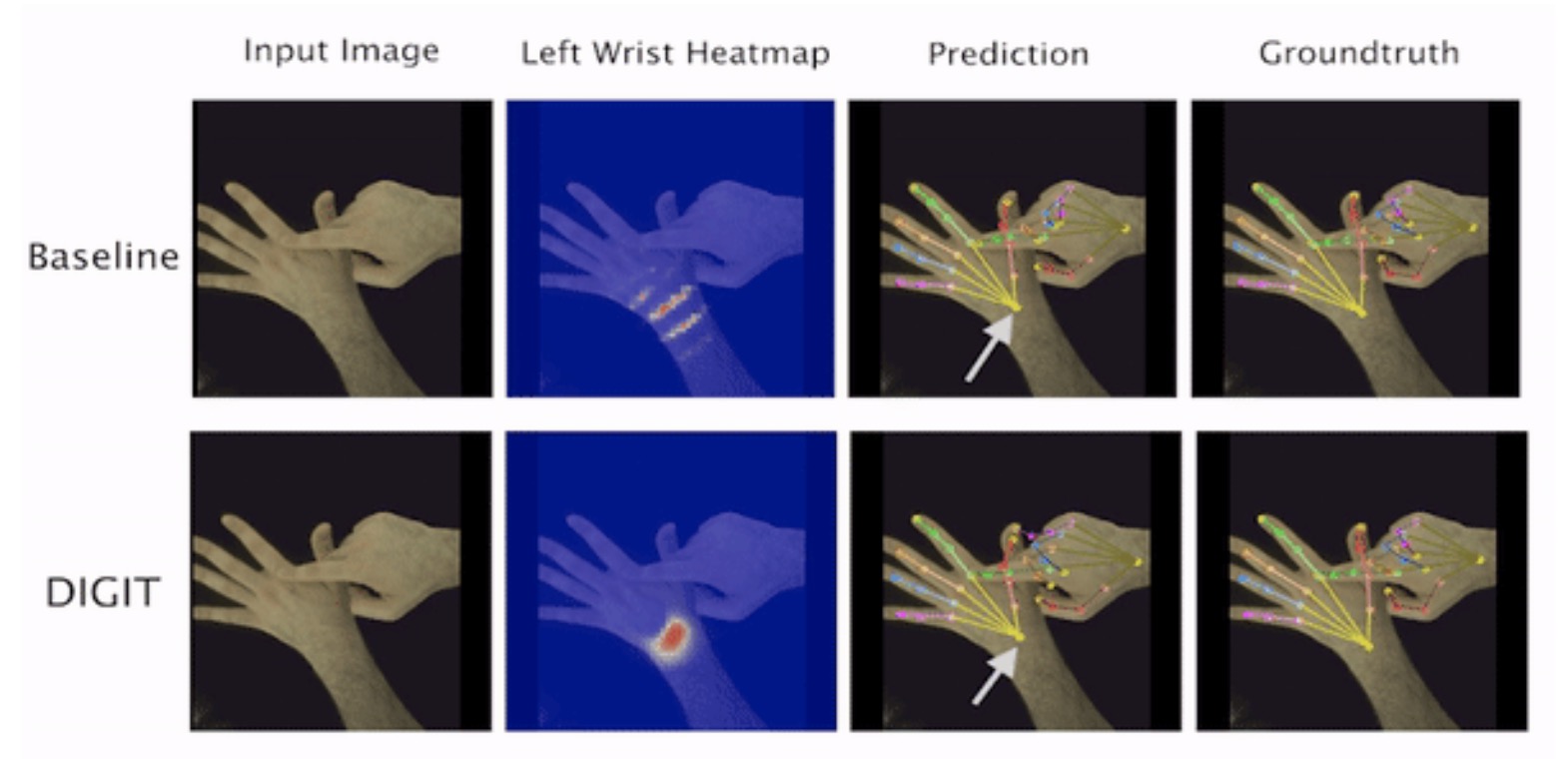
Authors: Zicong Fan, Adrian Spurr, Muhammed Kocabas, Siyu Tang, Michael J. Black and Otmar Hilliges
In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image.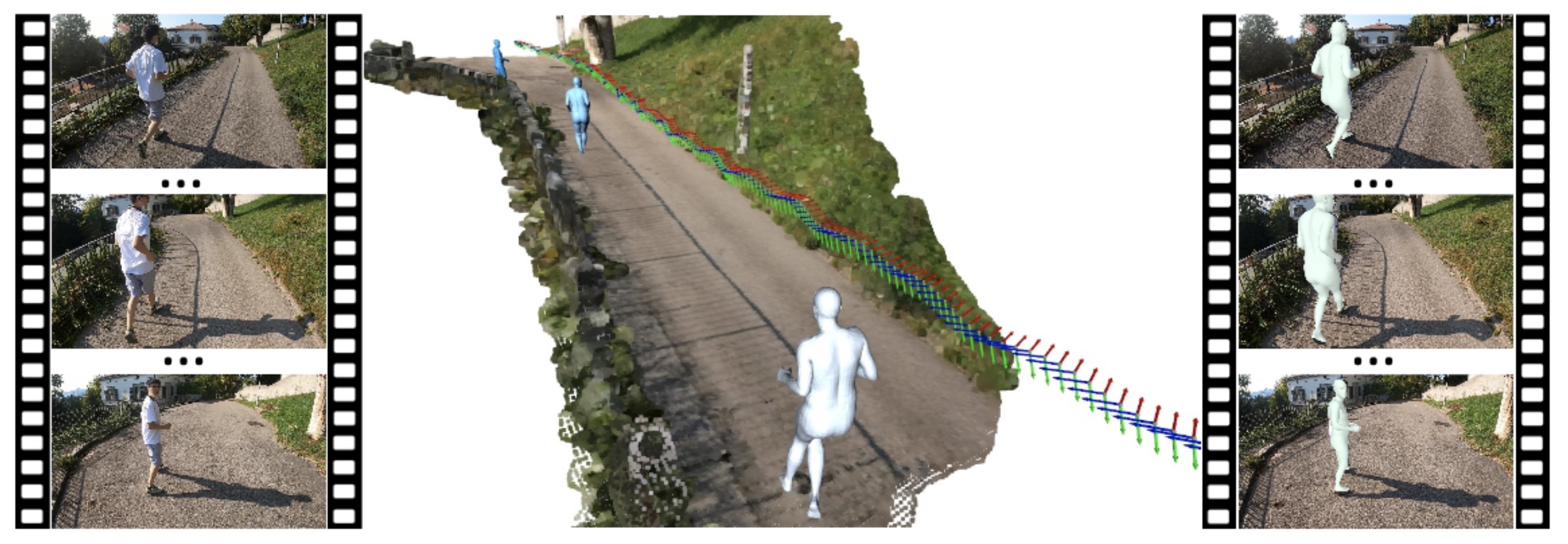
Authors: Miao Liu, Dexin Yang, Yan Zhang, Zhaopeng Cui, James M. Rehg, Siyu Tang
We seek to reconstruct 4D second-person human body meshes that are grounded on the 3D scene captured in an egocentric view. Our method exploits 2D observations from the entire video sequence and the 3D scene context to optimize human body models over time, and thereby leads to more accurate human motion capture and more realistic human-scene interaction.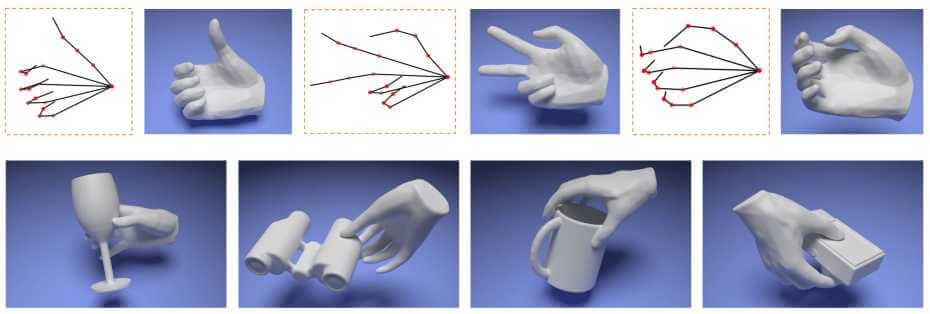
Authors: Korrawe Karunratanakul, Adrian Spurr, Zicong Fan, Otmar Hilliges, Siyu Tang
We present HALO, a neural occupancy representation for articulated hands that produce implicit hand surfaces from input skeletons in a differentiable manner.
Authors: Qianli Ma, Jinlong Yang, Siyu Tang and Michael J. Black
We introduce POP — a point-based, unified model for multiple subjects and outfits that can turn a single, static 3D scan into an animatable avatar with natural pose-dependent clothing deformations.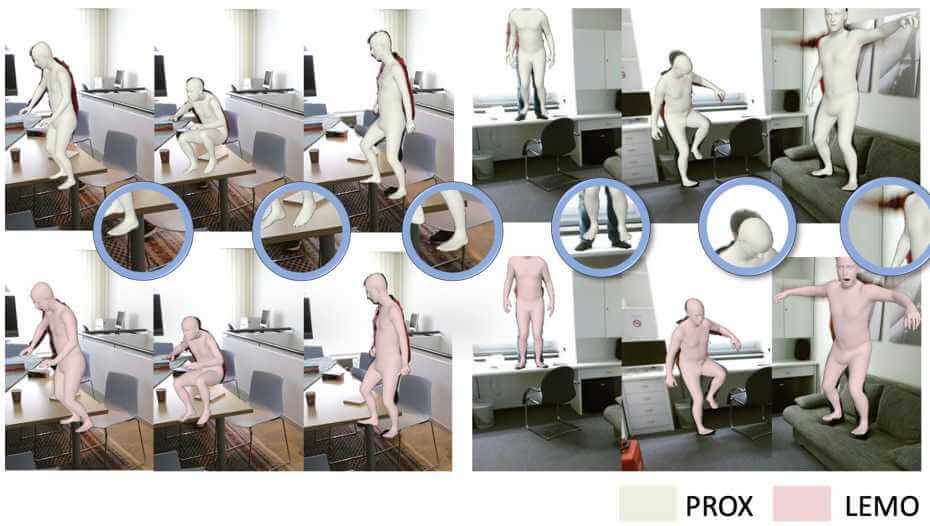
Learning Motion Priors for 4D Human Body Capture in 3D Scenes
Conference: International Conference on Computer Vision (ICCV 2021) oral presentation
Authors: Siwei Zhang, Yan Zhang, Federica Bogo, Marc Pollefeys and Siyu Tang
LEMO learns motion priors from a larger scale mocap dataset and proposes a multi-stage optimization pipeline to enable 3D motion reconstruction in complex 3D scenes.
On Self-Contact and Human Pose
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2021) oral presentation & best paper finalist
Authors: Lea Müller, Ahmed A. A. Osman, Siyu Tang, Chun-Hao P. Huang and Michael J. Black
we develop new datasets and methods that significantly improve human pose estimation with self-contact.

Authors: Marko Mihajlovic, Yan Zhang, Michael J. Black and Siyu Tang
LEAP is a neural network architecture for representing volumetric animatable human bodies. It follows traditional human body modeling techniques and leverages a statistical human prior to generalize to unseen humans.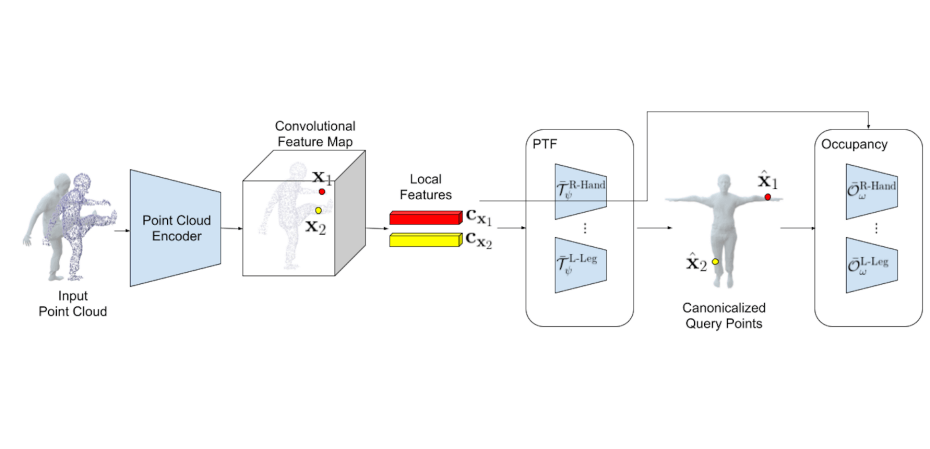
Authors: Shaofei Wang, Andreas Geiger and Siyu Tang
Registering point clouds of dressed humans to parametric human models is a challenging task in computer vision. We propose novel piecewise transformation fields (PTF), a set of functions that learn 3D translation vectors which facilitates occupancy learning, joint-rotation estimation and mesh registration.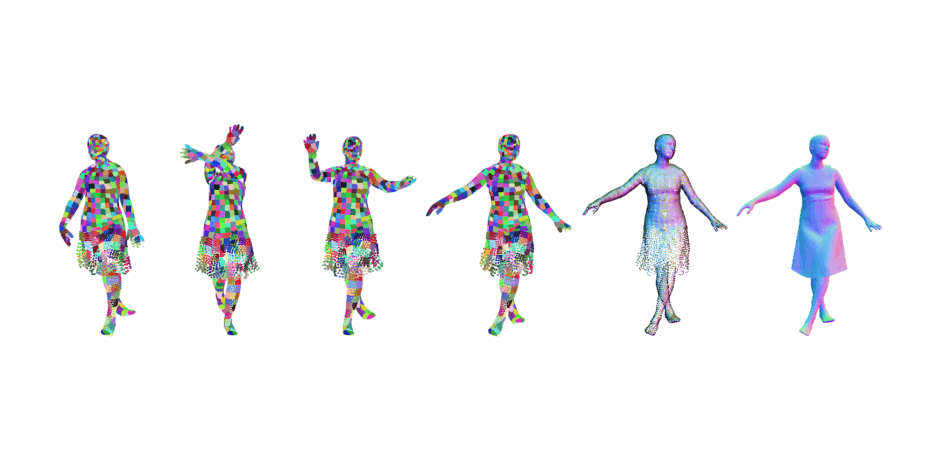
Authors: Qianli Ma, Shunsuke Saito, Jinlong Yang, Siyu Tang and Michael J. Black
SCALE models 3D clothed humans with hundreds of articulated surface elements, resulting in avatars with realistic clothing that deforms naturally even in the presence of topological change.2020
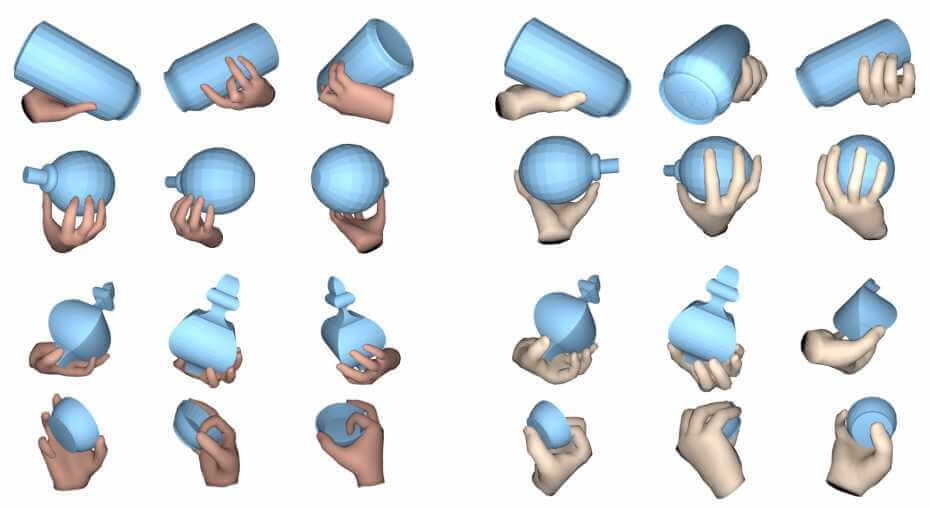
Grasping Field: Learning Implicit Representations for Human Grasps
Conference: International Virtual Conference on 3D Vision (3DV) 2020 oral presentation & best paper
Authors: Korrawe Karunratanakul, Jinlong Yang, Yan Zhang, Michael Black, Krikamol Muandet, Siyu Tang
Capturing and synthesizing hand-object interaction is essential for understanding human behaviours, and is key to a number of applications including VR/AR, robotics and human-computer interaction.
Authors: Siwei Zhang, Yan Zhang, Qianli Ma, Michael J. Black, Siyu Tang
Automated synthesis of realistic humans posed naturally in a 3D scene is essential for many applications. In this paper we propose explicit representations for the 3D scene and the person-scene contact relation in a coherent manner.
Authors: Yan Zhang, Michael J. Black, Siyu Tang
In this work, our goal is to generate significantly longer, or “perpetual”, motion: given a short motion sequence or even a static body pose, the goal is to generate non-deterministic ever-changing human motions in the future.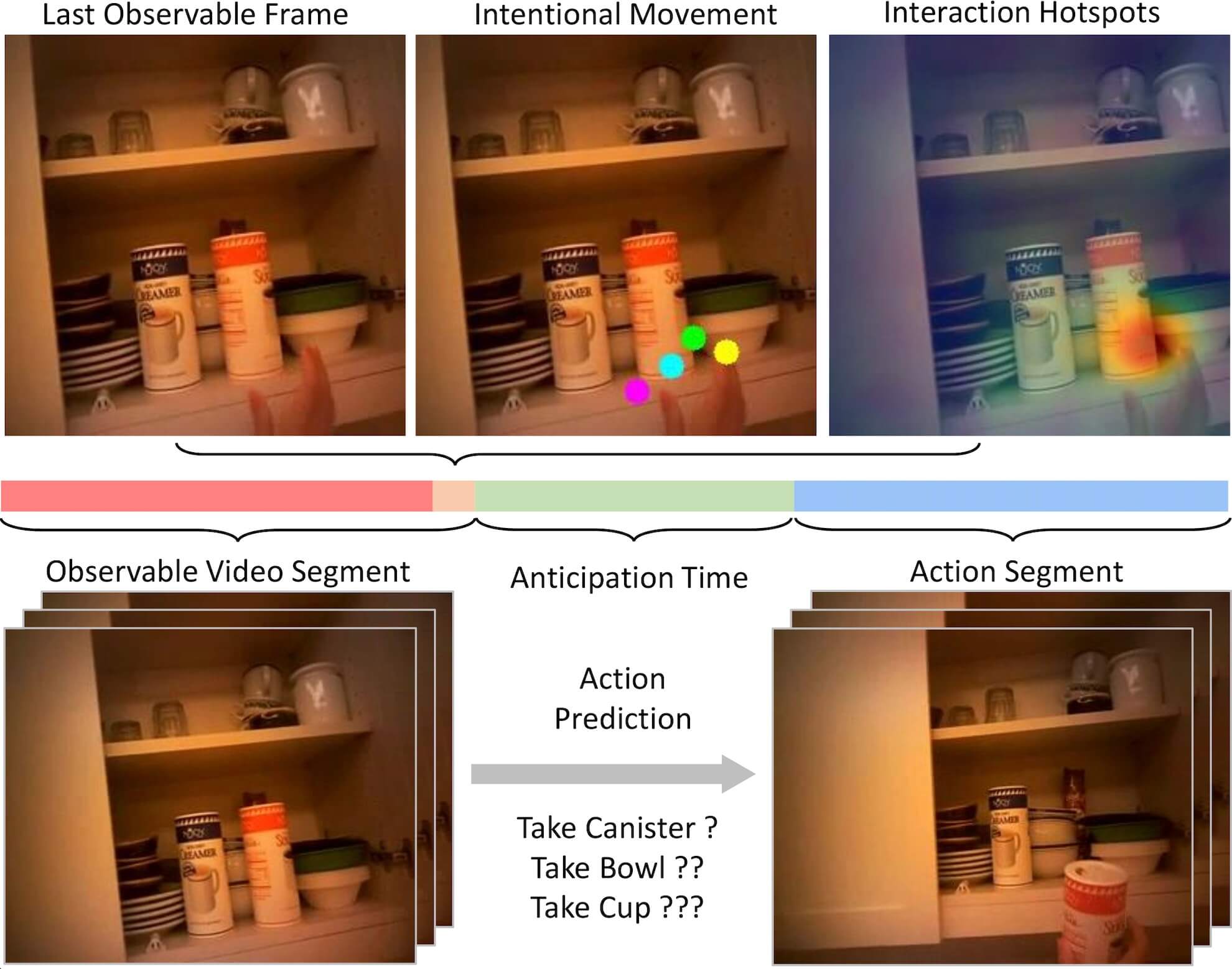
Authors: Miao Liu, Siyu Tang, Yin Li, and James M. Rehg
We address the challenging task of anticipating human-object interaction in first person videos. We adopt intentional hand movement as a future representation and propose a novel deep network that jointly models and predicts the egocentric hand motion, interaction hotspots and future action.
Authors: Xucong Zhang, Seonwook Park, Thabo Beeler, Derek Bradley, Siyu Tang , Otmar Hilliges
We propose the ETH-XGaze dataset: a large scale (over 1 million samples) gaze estimation dataset with high-resolution images under extreme head poses and gaze directions.
Generating 3D People in Scenes without People
Conference: Computer Vision and Pattern Recognition (CVPR) 2020 oral presentation
Authors: Yan Zhang, Mohamed Hassan, Heiko Neumann, Michael J. Black, Siyu Tang
We present a fully-automatic system that takes a 3D scene and generates plausible 3D human bodies that are posed naturally in that 3D scene.
Authors: Qianli Ma, Jinlong Yang, Anurag Ranjan, Sergi Pujades, Gerard Pons-Moll, Siyu Tang, and Michael J. Black
CAPE is a Graph-CNN based generative model for dressing 3D meshes of human body. It is compatible with the popular body model, SMPL, and can generalize to diverse body shapes and body poses. The CAPE Dataset provides SMPL mesh registration of 4D scans of people in clothing, along with registered scans of the ground truth body shapes under clothing.
Authors: Anurag Ranjan, David T. Hoffmann, Dimitrios Tzionas, Siyu Tang, Javier Romero, Michael J. Black
We created an extensive Human Optical Flow dataset containing images of realistic human shapes in motion together with ground truth optical flow. We then train two compact network architectures based on spatial pyramids, namely SpyNet and PWC-Net.
Authors: Jie Song, Bjoern Andres, Michael J. Black, Otmar Hilliges, Siyu Tang
We propose an end-to-end trainable framework to learn feature representations globally in a graph decomposition problem.