Keep up to date with what we're working on!
Recovering accurate 3D human pose and motion in complex scenes from monocular in-the-wild videos is essential for many applications. However, capturing realistic human motion while dealing with occlusions and partial views is challenging. Our group has made several contributions in developing robust and reliable methods that address this task.
Generative human body models are powerful tools for estimating 3D human bodies from partial observations. Our group has proposed several novel methods in the rising research area of learning neural implicit body models.
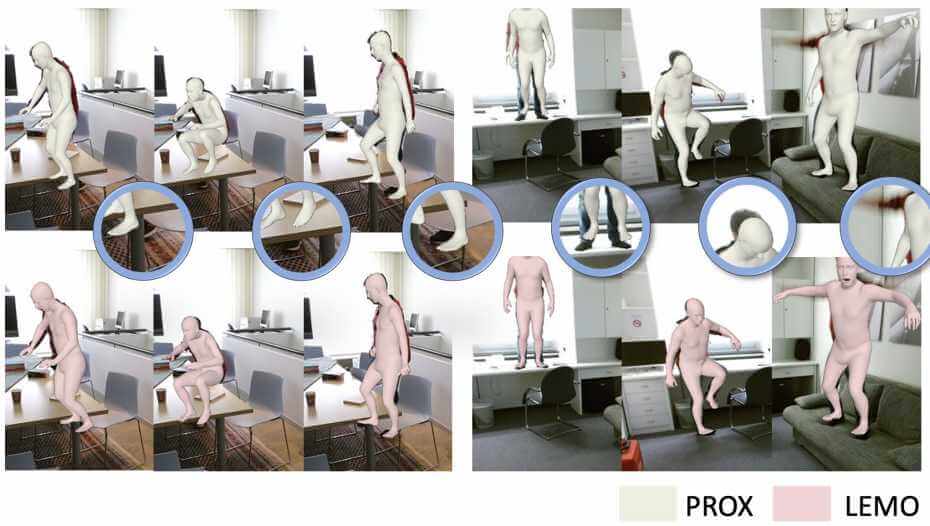
A key step towards understanding human behavior is predicting 3D human motion. Our group has made several contributions in this direction. First, we focused on learning robust and efficient marker-based representations of 3D human bodies in motion. We proposed new generative motion models and optimization algorithms to synthesize realistic human motion sequences. Second, we developed an efficient and fully automated system to generate long-term, even infinite motion for various human shapes.
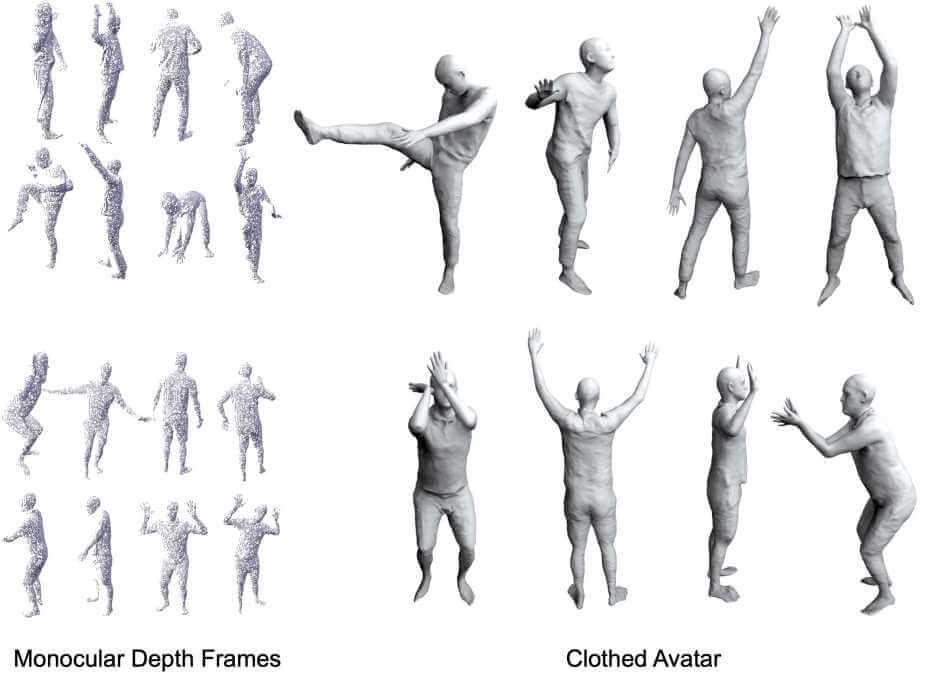
Human avatar creation is required in many applications. Commercial solutions have made tremendous progress in recent years, such as MetaHuman from Unreal. Yet, creating these avatars still needs significant artist efforts. Recent advances in deep learning, mainly neural implicit representations, have enabled controllable human avatar generation from different sensory inputs. However, to generate realistic cloth deformations from novel input poses, watertight meshes or dense full-body scans are usually needed as inputs. Our group has focused on advancing the frontier of realistic human avatar creation from affordable commodity sensors, such as a monocular RGB(D) camera.
With the continuous advancement of mobile processing and the increasing availability of extended reality (XR) headsets, extended reality will soon become available to the masses. We Envision a future world where humans, objects, and scenes from the physical and digital worlds are merged. In this embodied and immersive future, the ability to understand humans is essential for extended reality headsets.