Recovering accurate 3D human pose and motion in complex scenes from monocular in-the-wild videos is essential for many applications. However, capturing realistic human motion while dealing with occlusions and partial views is challenging. Our group has made several important contributions in developing robust and reliable methods that address this task. First, we developed novel learning-based piecewise transformation fields that estimate 3D human body pose and shape from monocular depth input. Our approach circumvents the challenging task of directly regressing human body joint rotations from neural networks, significantly outperforms previous methods. Second, we addressed the task of accurate human motion reconstruction by learning robust human motion priors from large-scale motion capture datasets, enabling a lightweight mocap system for 4D human body capture in 3D scenes. Third, we proposed new datasets and an optimization framework for human pose estimation with self-contact, which is ubiquitous in human behavior. Our work significantly improved the physical plausibility of the reconstructed 3D human bodies and was a candidate for the Best Paper Award at CVPR 2021.
Publications
Authors:Miao Liu, Dexin Yang, Yan Zhang, Zhaopeng Cui, James M. Rehg, Siyu Tang
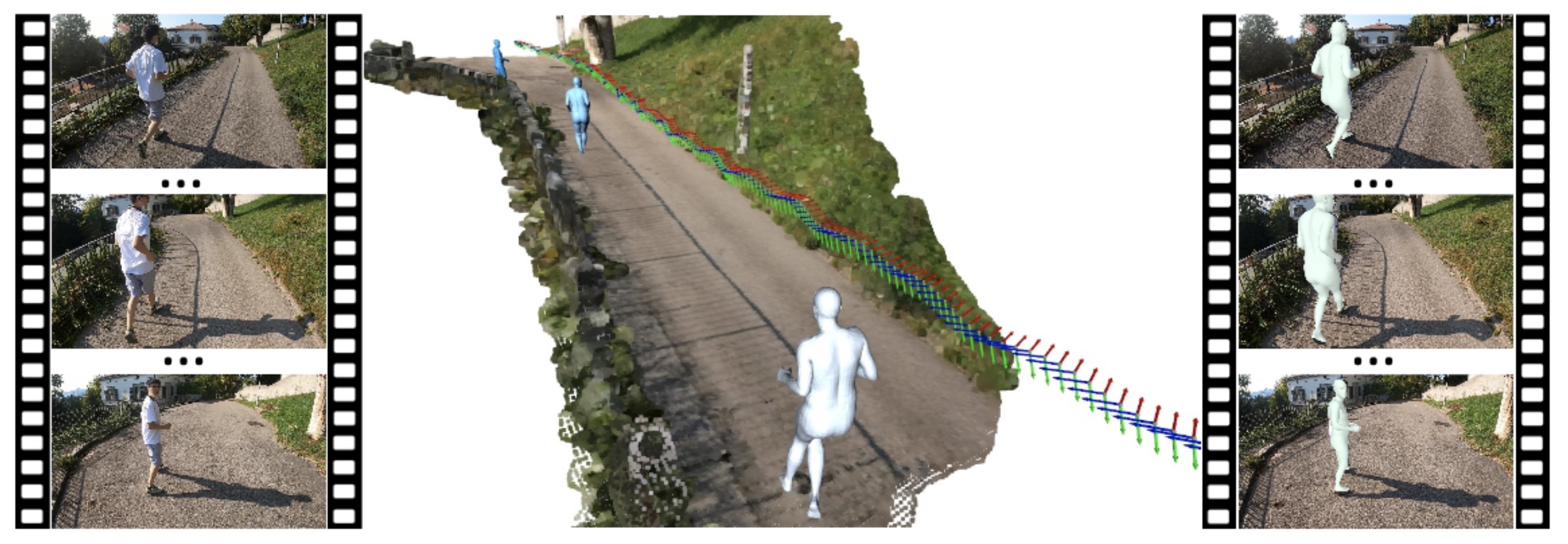
We seek to reconstruct 4D second-person human body meshes that are grounded on the 3D scene captured in an egocentric view. Our method exploits 2D observations from the entire video sequence and the 3D scene context to optimize human body models over time, and thereby leads to more accurate human motion capture and more realistic human-scene interaction.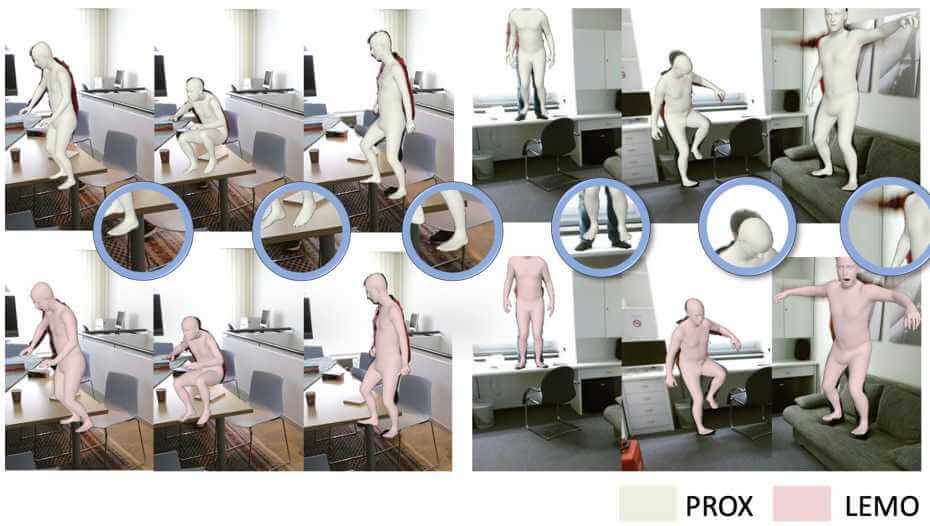
Learning Motion Priors for 4D Human Body Capture in 3D Scenes
Conference: International Conference on Computer Vision (ICCV 2021) oral presentation
Authors:Siwei Zhang, Yan Zhang, Federica Bogo, Marc Pollefeys and Siyu Tang
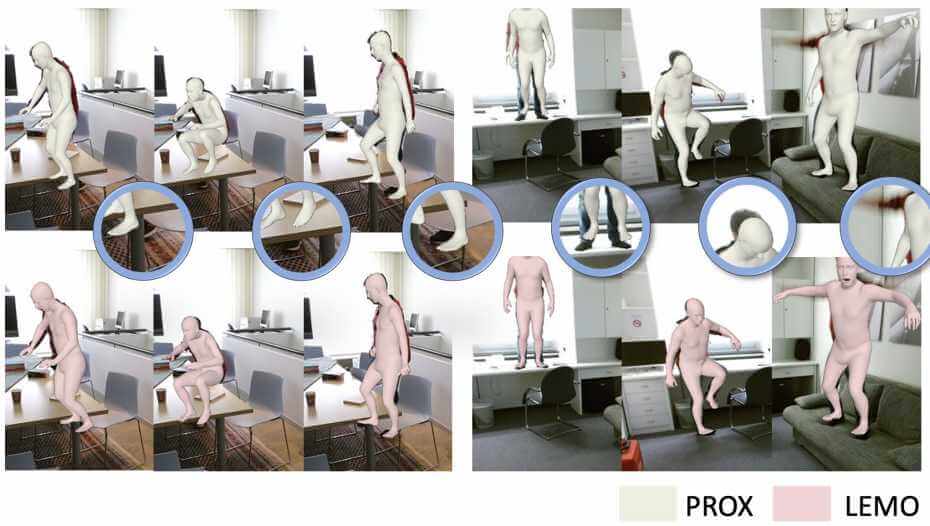
LEMO learns motion priors from a larger scale mocap dataset and proposes a multi-stage optimization pipeline to enable 3D motion reconstruction in complex 3D scenes.
On Self-Contact and Human Pose
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2021) oral presentation & best paper finalist
Authors:Lea Müller, Ahmed A. A. Osman, Siyu Tang, Chun-Hao P. Huang and Michael J. Black
we develop new datasets and methods that significantly improve human pose estimation with self-contact.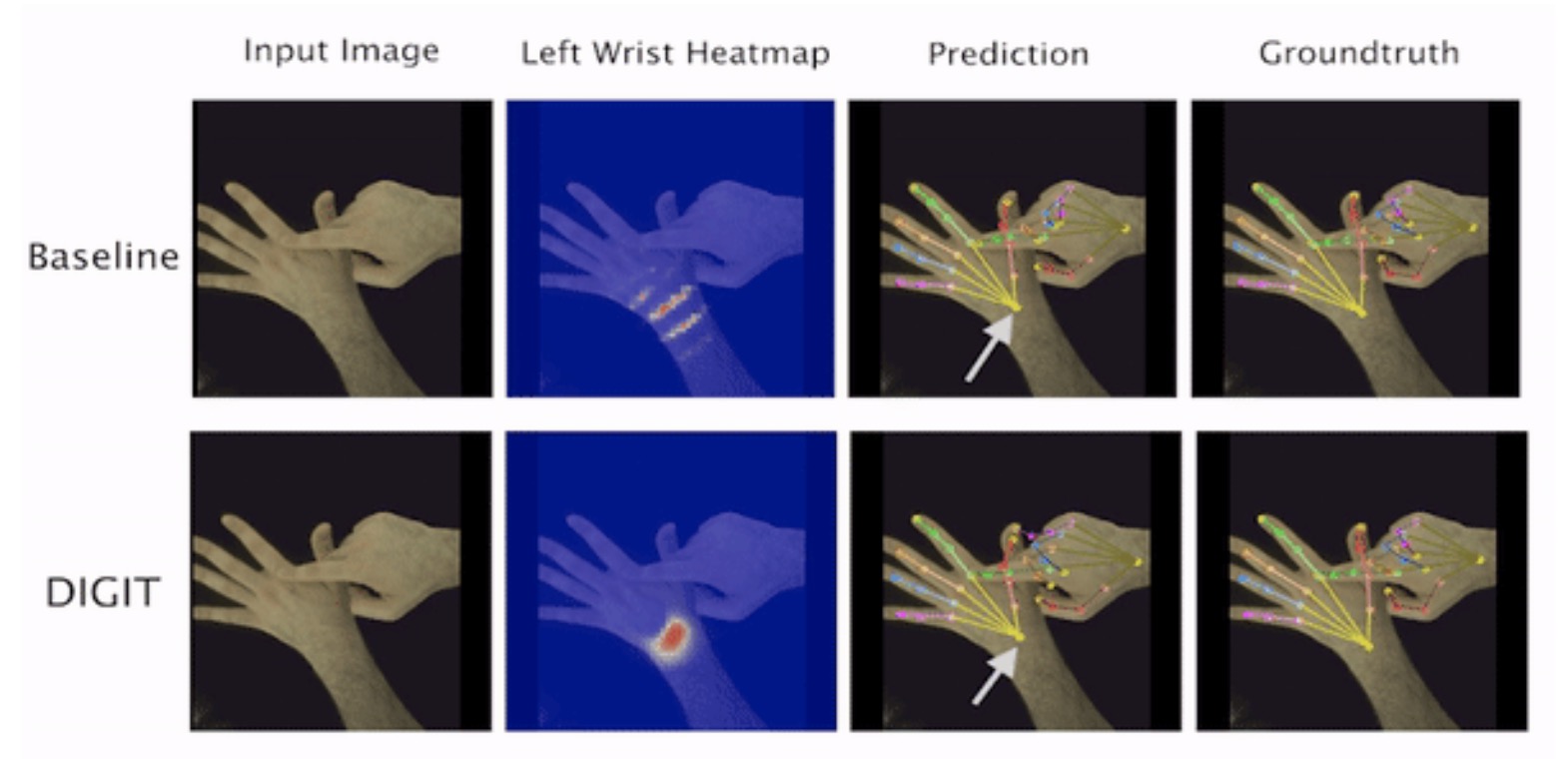
Authors:Zicong Fan, Adrian Spurr, Muhammed Kocabas, Siyu Tang, Michael J. Black and Otmar Hilliges
In this paper we demonstrate that self-similarity, and the resulting ambiguities in assigning pixel observations to the respective hands and their parts, is a major cause of the final 3D pose error. Motivated by this insight, we propose DIGIT, a novel method for estimating the 3D poses of two interacting hands from a single monocular image.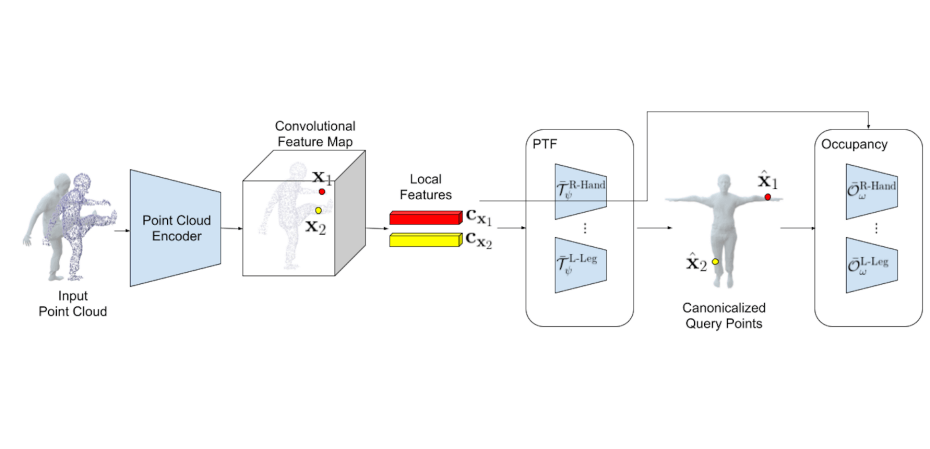
Authors:Shaofei Wang, Andreas Geiger and Siyu Tang
Registering point clouds of dressed humans to parametric human models is a challenging task in computer vision. We propose novel piecewise transformation fields (PTF), a set of functions that learn 3D translation vectors which facilitates occupancy learning, joint-rotation estimation and mesh registration.
Authors:Jie Song, Bjoern Andres, Michael J. Black, Otmar Hilliges, Siyu Tang
We propose an end-to-end trainable framework to learn feature representations globally in a graph decomposition problem.