
Basic Information
I am dedicated on human-centered AI, in particular on human behavior perceiving and synthesis in 3D scenes. This is an intersection area between computer vision, machine learning, computer graphics, robotics, and cognitive science. The goal is to capture high-quality human motions and infer behavioural intentions from various modalities, learn generative models of human behaviour, and synthesize it in novel environments. The core scientific challenge is to understand why and how our bodies move. The donwstream applications include digital scene population, synthetic data creation, computer-aidded design, game/VFX, smart home, healthcare, and beyond. I am actively exploring and implementing solutions to real world problems, in order to make our lives better.
I am currently a postdoc researcher at Computer Vision and Learning Group (VLG), ETH Zurich, working with Prof. Siyu Tang. Before I was a research intern at Perceiving Systems Department, MPI Tuebingen, working with Prof. Michael J. Black. I got my PhD degree at Ulm University with magna cum laude, supervised by Prof. Heiko Neumann.
Social
Publications

Authors:Kaifeng Zhao, Yan Zhang, Shaofei Wang, Thabo Beeler, Siyu Tang
Interaction with environments is one core ability of virtual humans and remains a challenging problem. We propose a method capable of generating a sequence of natural interaction events in real cluttered scenes.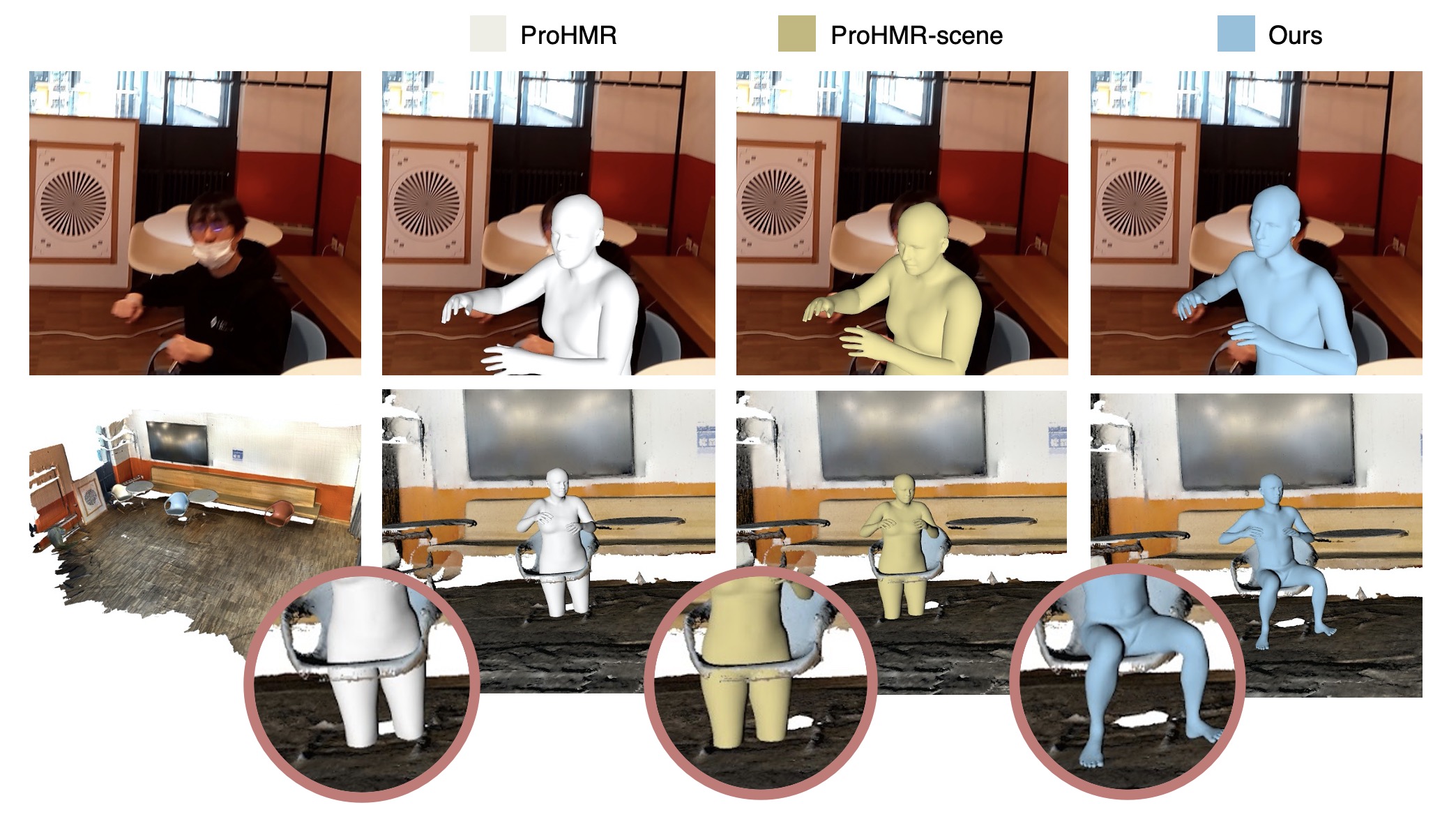
Authors:Siwei Zhang, Qianli Ma, Yan Zhang, Sadegh Aliakbarian, Darren Cosker, Siyu Tang
We propose a novel scene-conditioned probabilistic method to recover the human mesh from an egocentric view image (typically with the body truncated) in the 3D environment.
Authors:Siwei Zhang, Qianli Ma, Yan Zhang, Zhiyin Qian, Taein Kwon, Marc Pollefeys, Federica Bogo and Siyu Tang
A large-scale dataset of accurate 3D human body shape, pose and motion of humans interacting in 3D scenes, with multi-modal streams from third-person and egocentric views, captured by Azure Kinects and a HoloLens2.
Authors:Kaifeng Zhao, Shaofei Wang, Yan Zhang, Thabo Beeler, Siyu Tang
Synthesizing natural interactions between virtual humans and their 3D environments is critical for numerous applications, such as computer games and AR/VR experiences. We propose COINS, for COmpositional INteraction Synthesis with Semantic Control.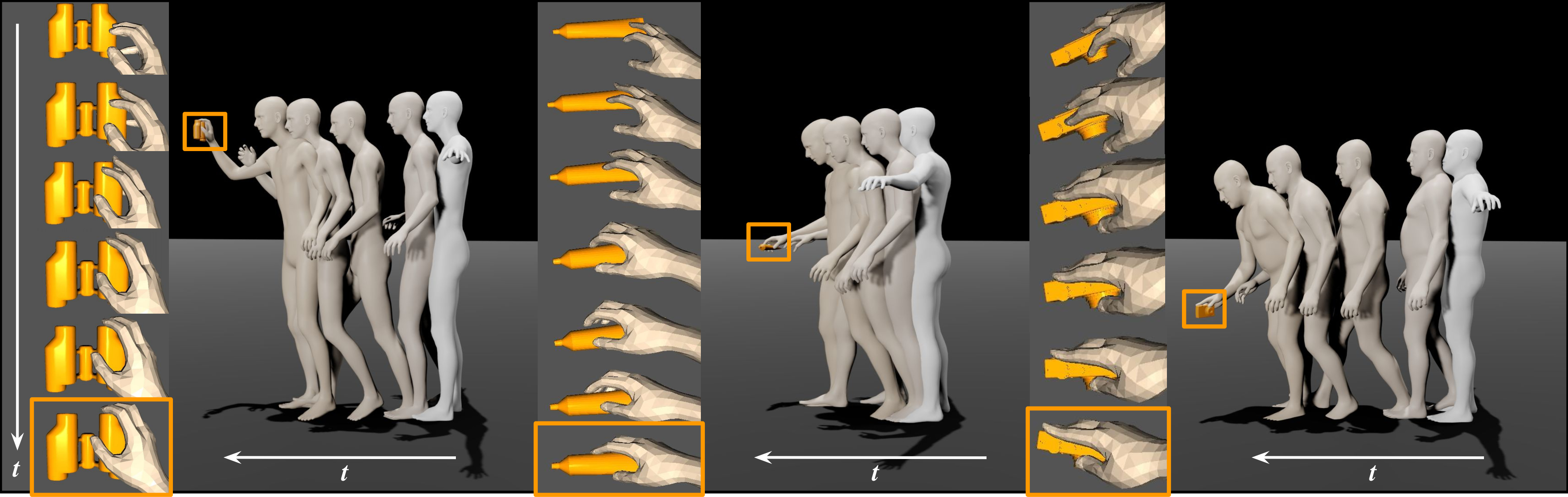
Authors:Yan Wu*, Jiahao Wang*, Yan Zhang, Siwei Zhang, Otmar Hilliges, Fisher Yu and Siyu Tang
(* denotes equal contribution)

We propose GAMMA, an automatic and scalable solution, to populate the 3D scene with diverse digital humans. The digital humans have 1) varied body shapes, 2) realistic and perpetual motions to reach goals, and 3) plausible body-ground contact.
Learning Motion Priors for 4D Human Body Capture in 3D Scenes
Conference: International Conference on Computer Vision (ICCV 2021) oral presentation
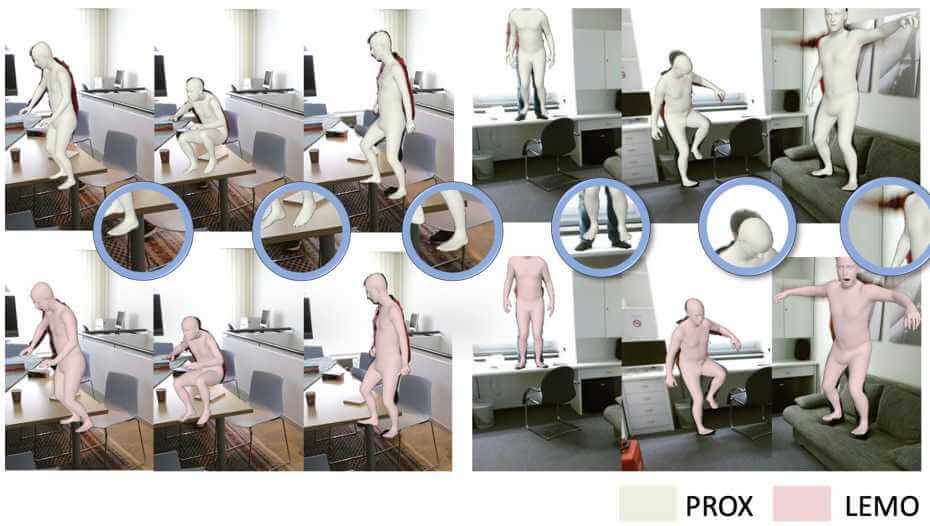
Authors:Siwei Zhang, Yan Zhang, Federica Bogo, Marc Pollefeys and Siyu Tang
LEMO learns motion priors from a larger scale mocap dataset and proposes a multi-stage optimization pipeline to enable 3D motion reconstruction in complex 3D scenes.

Authors:Marko Mihajlovic, Yan Zhang, Michael J. Black and Siyu Tang
LEAP is a neural network architecture for representing volumetric animatable human bodies. It follows traditional human body modeling techniques and leverages a statistical human prior to generalize to unseen humans.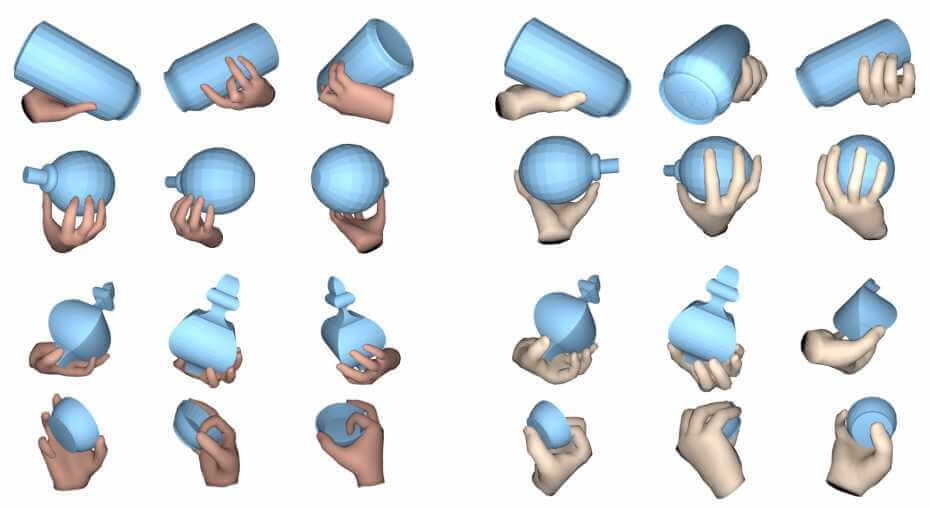
Grasping Field: Learning Implicit Representations for Human Grasps
Conference: International Virtual Conference on 3D Vision (3DV) 2020 oral presentation & best paper
Authors:Korrawe Karunratanakul, Jinlong Yang, Yan Zhang, Michael Black, Krikamol Muandet, Siyu Tang
Capturing and synthesizing hand-object interaction is essential for understanding human behaviours, and is key to a number of applications including VR/AR, robotics and human-computer interaction.
Authors:Siwei Zhang, Yan Zhang, Qianli Ma, Michael J. Black, Siyu Tang
Automated synthesis of realistic humans posed naturally in a 3D scene is essential for many applications. In this paper we propose explicit representations for the 3D scene and the person-scene contact relation in a coherent manner.
Authors:Yan Zhang, Michael J. Black, Siyu Tang
In this work, our goal is to generate significantly longer, or “perpetual”, motion: given a short motion sequence or even a static body pose, the goal is to generate non-deterministic ever-changing human motions in the future.
Generating 3D People in Scenes without People
Conference: Computer Vision and Pattern Recognition (CVPR) 2020 oral presentation
Authors:Yan Zhang, Mohamed Hassan, Heiko Neumann, Michael J. Black, Siyu Tang
We present a fully-automatic system that takes a 3D scene and generates plausible 3D human bodies that are posed naturally in that 3D scene.