
Basic Information
I am a PhD student at Computer Vision and Learning Group (VLG), ETH Zürich, supervised by Professor Siyu Tang. Prior to this, I obtained my Master degree (2020) in Electrical Engineering and Information Technology, ETH Zürich, and Bachelor degree in Automation, Tsinghua University (2017).
My research focuses on human-scene interaction learning, human motion modelling and egocentric human understanding, particularly with the 3D scenes.
Talks
2nd International Ego4D Workshop @ ECCV 2022
EgoBody: Human Body Shape and Motion of Interacting People from Head-Mounted Devices.
Microsoft Swiss Joint Research Center 2022
Egocentric Interaction Capture for Mixed Reality.
Microsoft Swiss Joint Research Center 2021
Learning Motion Priors for 4D Human Body Capture in 3D Scenes.
Awards
Qualcomm Innovative Fellowship Europe 2023
Social
Publications

Authors:Zhiyin Qian, Siwei Zhang, Bharat Lal Bhatnagar, Federica Bogo, Siyu Tang
Given a monocular video captured from a static camera, MoRo robustly reconstructs accurate and physically plausible human motion, even under challenging occlusion scenarios.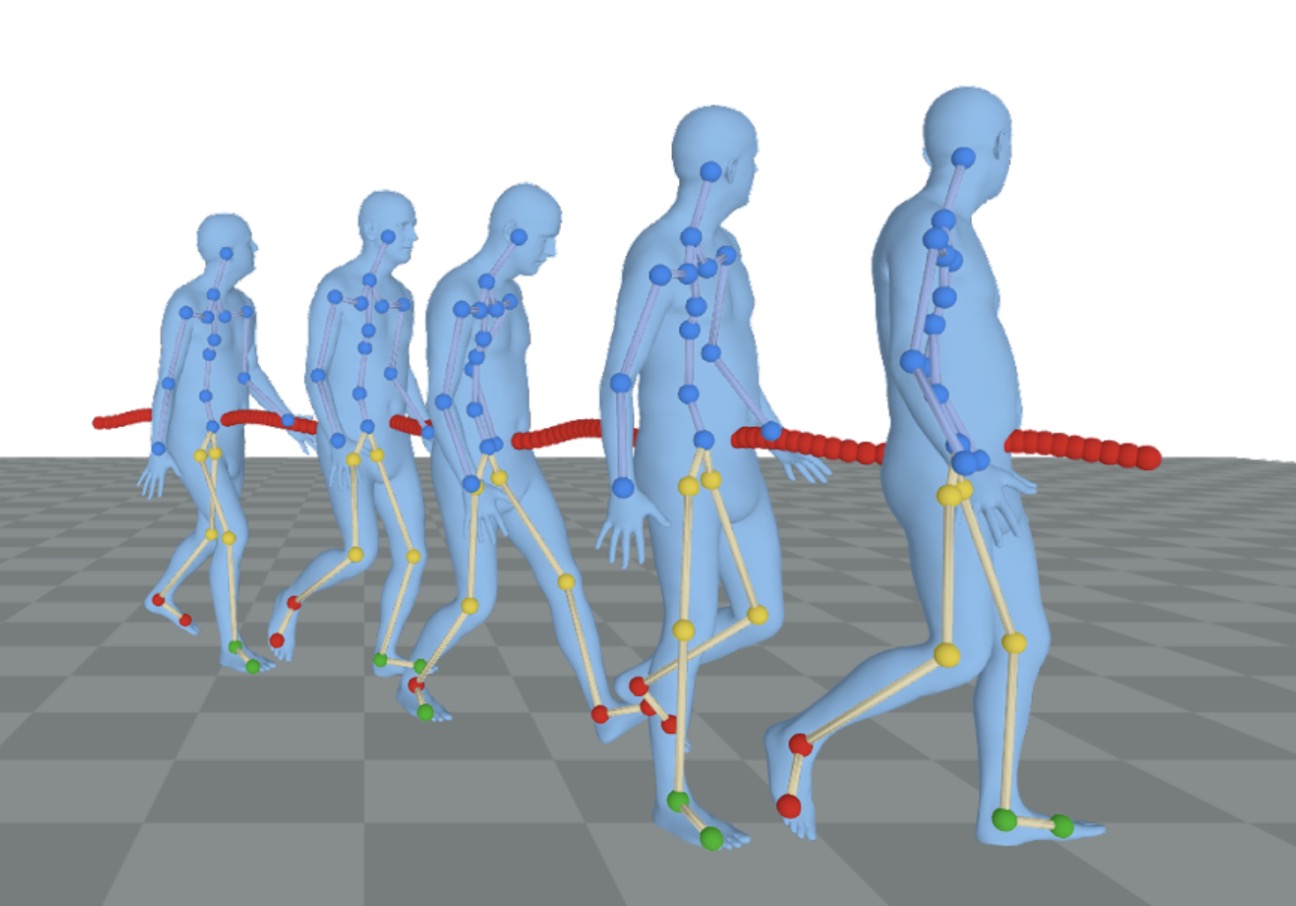
RoHM: Robust Human Motion Reconstruction via Diffusion
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2024) oral presentation
Authors:Siwei Zhang, Bharat Lal Bhatnagar, Yuanlu Xu, Alexander Winkler, Petr Kadlecek, Siyu Tang, Federica Bogo
Conditioned on noisy and occluded input data, RoHM reconstructs complete, plausible motions in consistent global coordinates.
EgoGen: An Egocentric Synthetic Data Generator
Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2024) oral presentation
Authors:Gen Li, Kaifeng Zhao, Siwei Zhang, Xiaozhong Lyu, Mihai Dusmanu, Yan Zhang, Marc Pollefeys, Siyu Tang
EgoGen is new synthetic data generator that can produce accurate and rich ground-truth training data for egocentric perception tasks.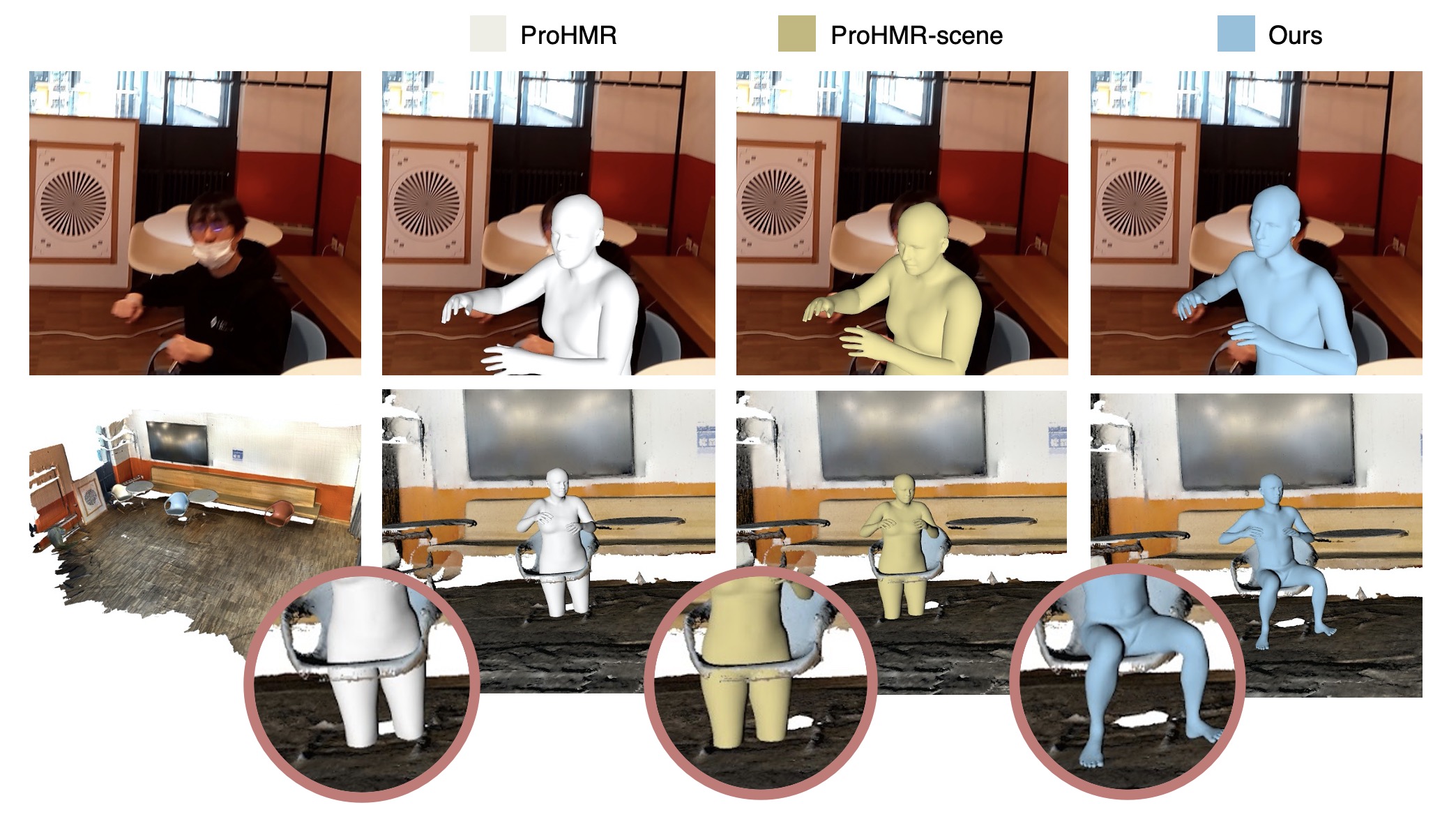
Authors:Siwei Zhang, Qianli Ma, Yan Zhang, Sadegh Aliakbarian, Darren Cosker, Siyu Tang
We propose a novel scene-conditioned probabilistic method to recover the human mesh from an egocentric view image (typically with the body truncated) in the 3D environment.
Authors:Rui Wang, Sophokles Ktistakis, Siwei Zhang, Mirko Meboldt, Quentin Lohmeyer
We propose POV-Surgery, a large-scale, synthetic, egocentric dataset focusing on pose estimation for hands with different surgical gloves and three orthopedic surgical instruments, namely scalpel, friem, and diskplacer.
Authors:Siwei Zhang, Qianli Ma, Yan Zhang, Zhiyin Qian, Taein Kwon, Marc Pollefeys, Federica Bogo and Siyu Tang
A large-scale dataset of accurate 3D human body shape, pose and motion of humans interacting in 3D scenes, with multi-modal streams from third-person and egocentric views, captured by Azure Kinects and a HoloLens2.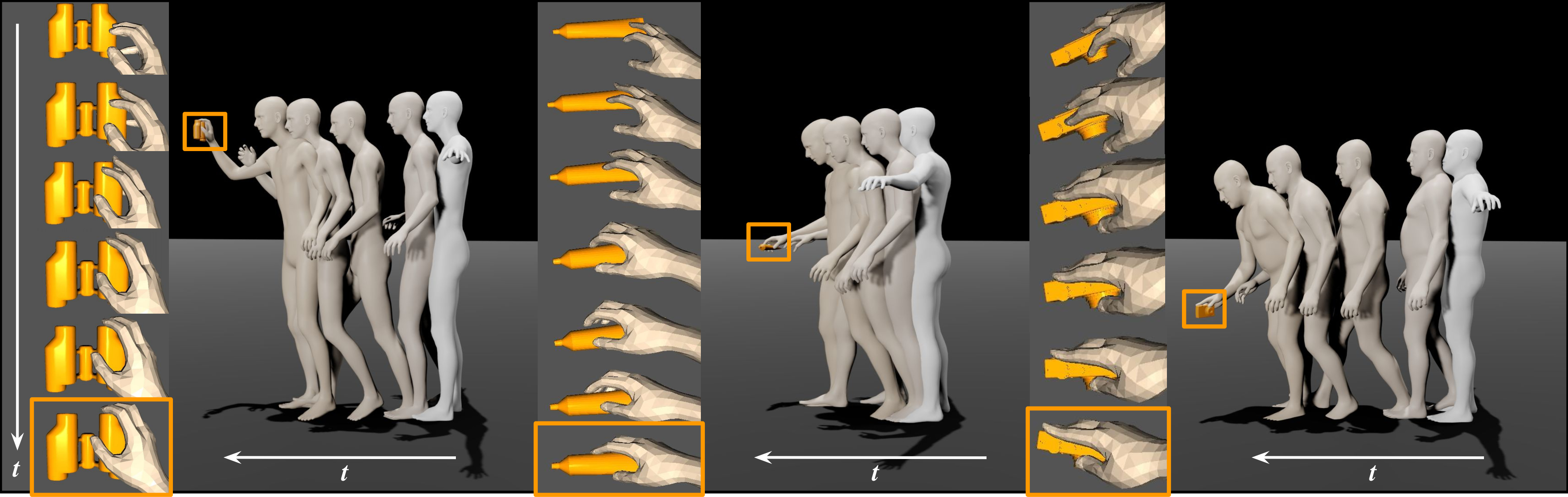
Authors:Yan Wu*, Jiahao Wang*, Yan Zhang, Siwei Zhang, Otmar Hilliges, Fisher Yu and Siyu Tang
(* denotes equal contribution)
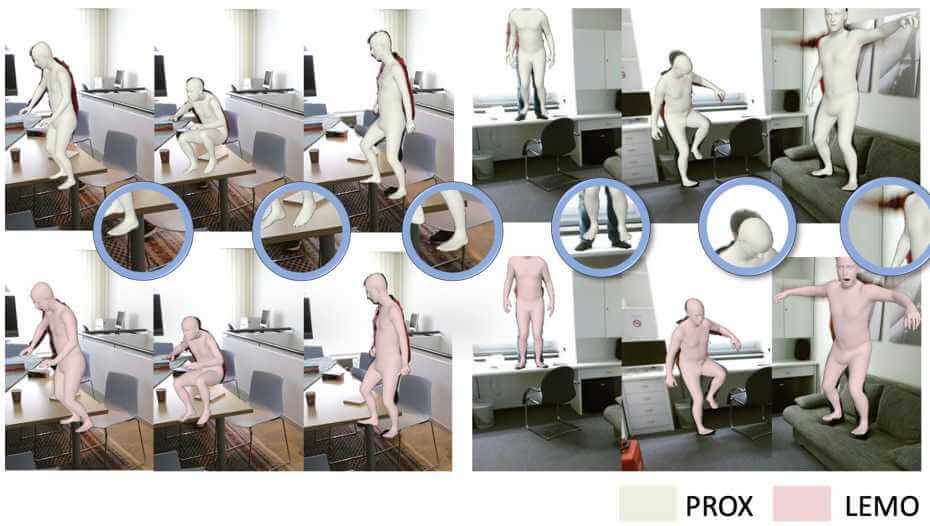
Learning Motion Priors for 4D Human Body Capture in 3D Scenes
Conference: International Conference on Computer Vision (ICCV 2021) oral presentation
Authors:Siwei Zhang, Yan Zhang, Federica Bogo, Marc Pollefeys and Siyu Tang
LEMO learns motion priors from a larger scale mocap dataset and proposes a multi-stage optimization pipeline to enable 3D motion reconstruction in complex 3D scenes.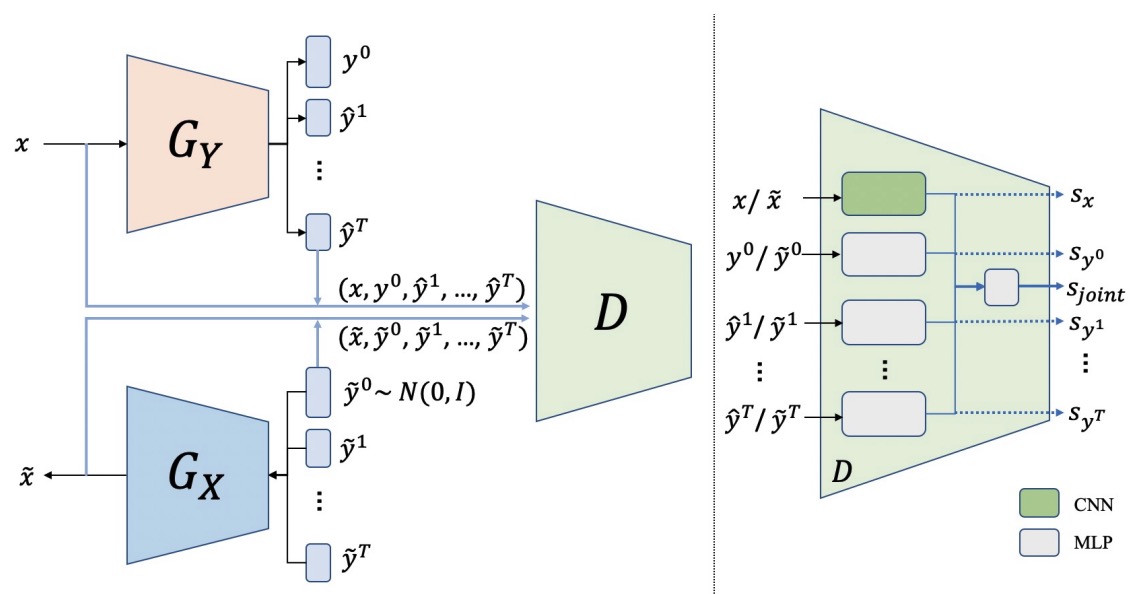
Authors:Siwei Zhang, Zhiwu Huang, Danda Pani Paudel, and Luc Van Gool
To reduce human labelling effort on multi-task labels, we introduce a new problem of facial emotion recognition with noisy multi-task annotations.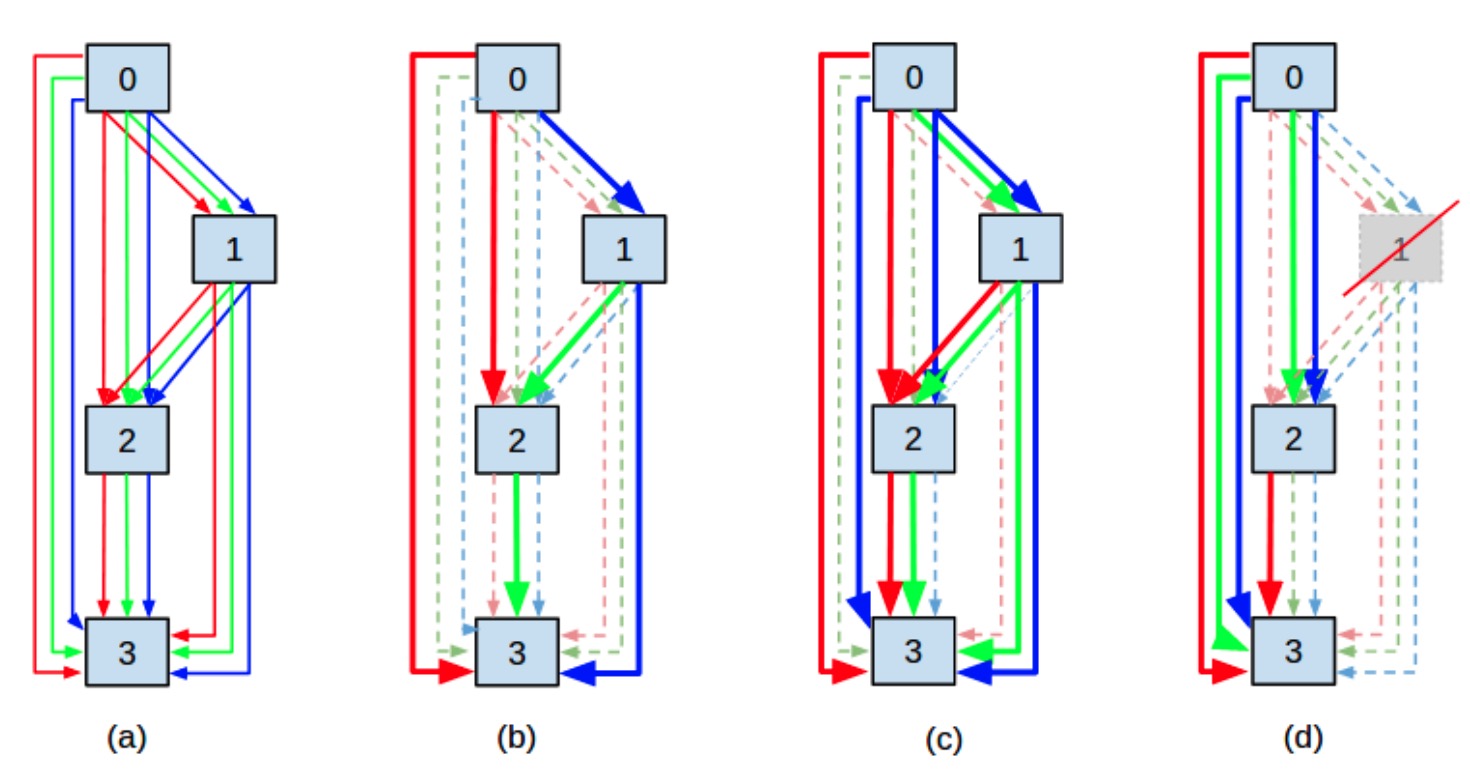
Authors:Yan Wu*; Aoming Liu*, Zhiwu Huang, Siwei Zhang, and Luc Van Gool
We model the NAS problem as a sparse supernet using a new continuous architecture representation with a mixture of sparsity constraints.
Authors:Siwei Zhang, Yan Zhang, Qianli Ma, Michael J. Black, Siyu Tang
Automated synthesis of realistic humans posed naturally in a 3D scene is essential for many applications. In this paper we propose explicit representations for the 3D scene and the person-scene contact relation in a coherent manner.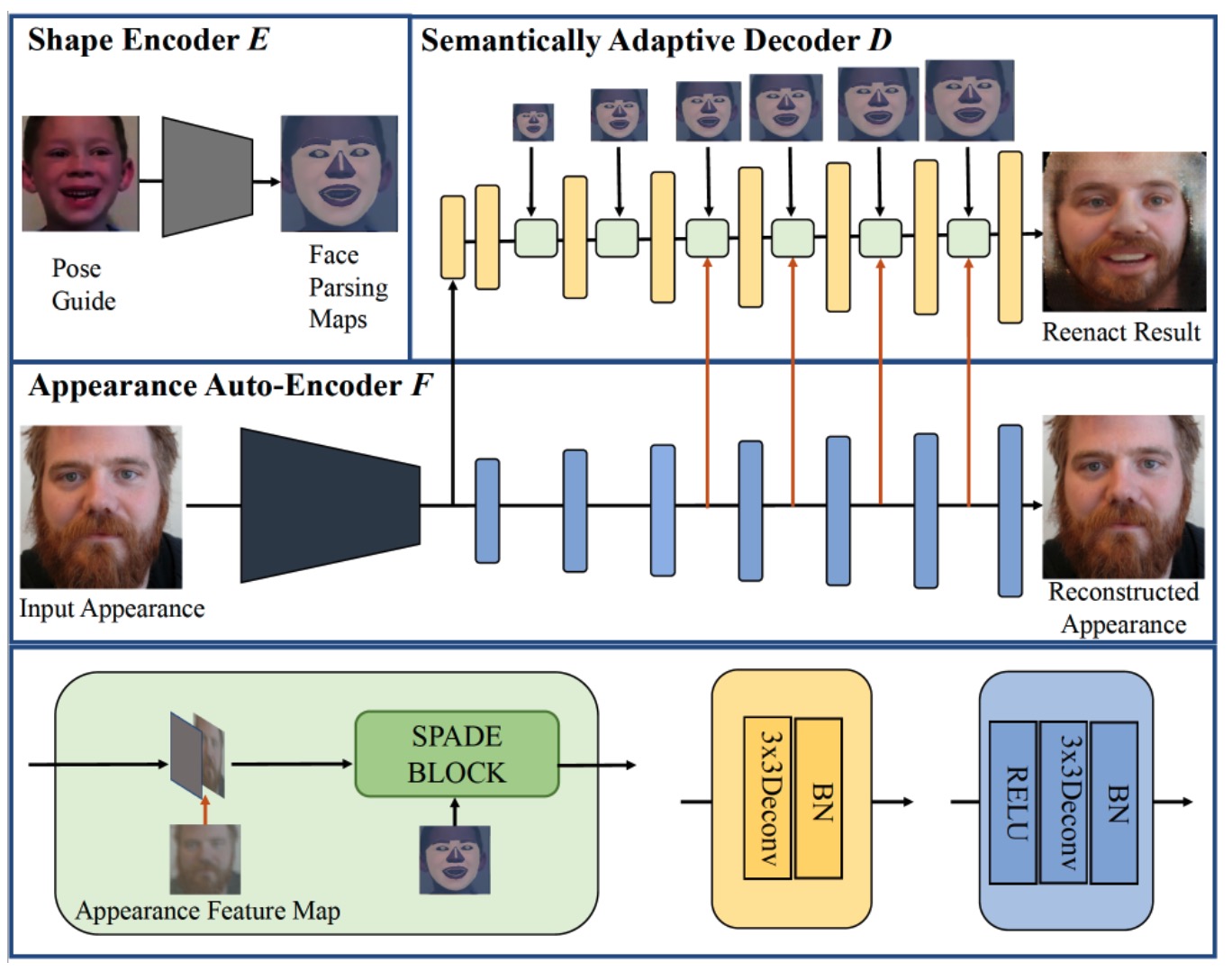
One-shot face reenactment
Conference: The British Machine Vision Conference (BMVC) 2019 spotlight presentation
Authors:Yunxuan Zhang, Siwei Zhang, Yue He, Cheng Li, Chen Change Loy, and Ziwei Liu
We propose a novel one-shot face reenactment learning system, that is able to disentangle and compose appearance and shape information for effective modeling.