
A key step towards understanding human behavior is predicting 3D human motion. Our group has made several contributions in this direction. First, we focused on learning robust and efficient marker-based representations of 3D human bodies in motion. We proposed new generative motion models and optimization algorithms to synthesize realistic human motion sequences. Second, we developed an efficient and fully automated system to generate long-term, even infinite motion for various human shapes. Specifically, given a 3D scene, e.g., digital architecture, our model can generate a massive number of virtual humans, who possess diverse body shapes, move perpetually, and have plausible body-scene contact in an automatic,efficient, scalable, and controllable manner. Besides top-tier scientific publications, our motion synthesis method is the key component for the exhibition of inhabiting a virtual city hosted by theGuggenheim Museum Bilbao.
Publications

Authors:Kaifeng Zhao, Shaofei Wang, Yan Zhang, Thabo Beeler, Siyu Tang
Synthesizing natural interactions between virtual humans and their 3D environments is critical for numerous applications, such as computer games and AR/VR experiences. We propose COINS, for COmpositional INteraction Synthesis with Semantic Control.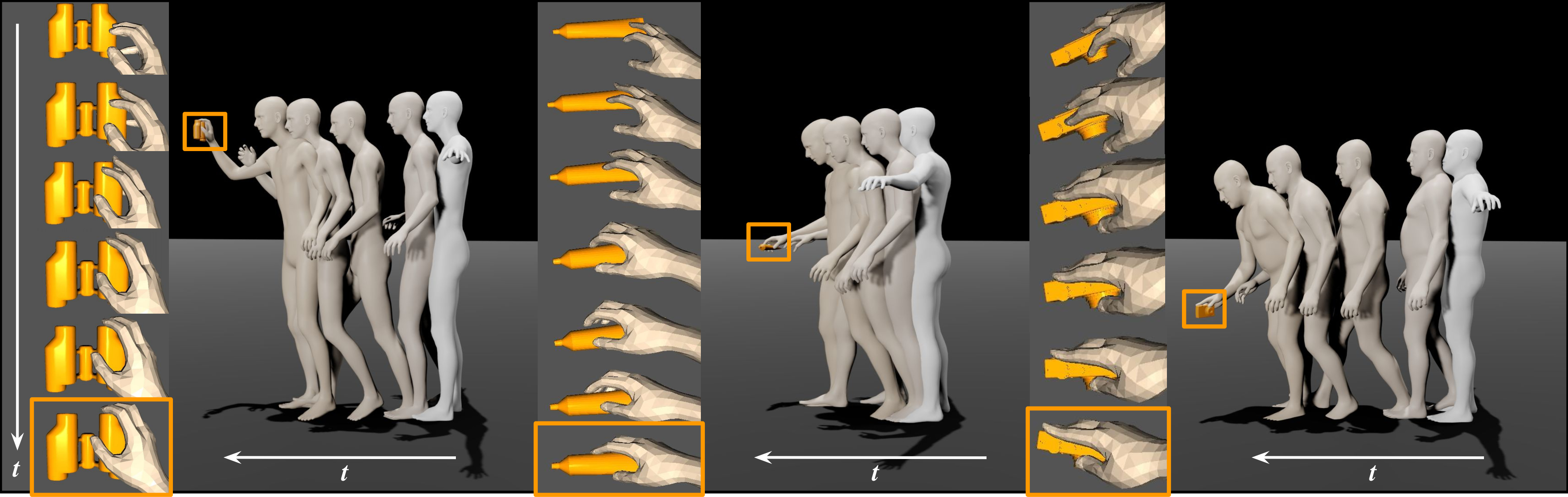
Authors:Yan Wu*, Jiahao Wang*, Yan Zhang, Siwei Zhang, Otmar Hilliges, Fisher Yu and Siyu Tang
(* denotes equal contribution)

We propose GAMMA, an automatic and scalable solution, to populate the 3D scene with diverse digital humans. The digital humans have 1) varied body shapes, 2) realistic and perpetual motions to reach goals, and 3) plausible body-ground contact.
Authors:Korrawe Karunratanakul, Adrian Spurr, Zicong Fan, Otmar Hilliges, Siyu Tang
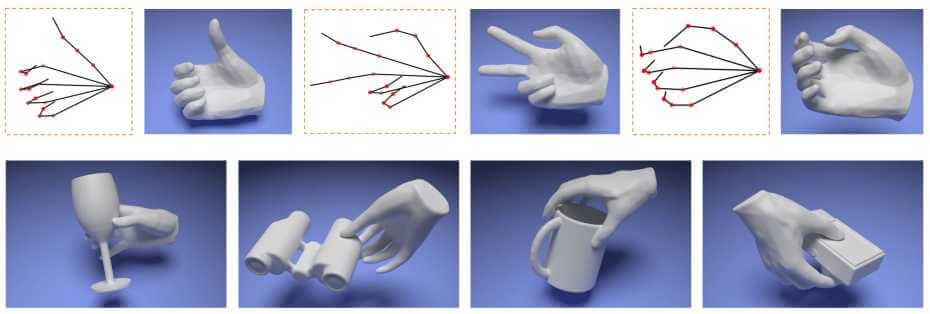
We present HALO, a neural occupancy representation for articulated hands that produce implicit hand surfaces from input skeletons in a differentiable manner.
Grasping Field: Learning Implicit Representations for Human Grasps
Conference: International Virtual Conference on 3D Vision (3DV) 2020 oral presentation & best paper
Authors:Korrawe Karunratanakul, Jinlong Yang, Yan Zhang, Michael Black, Krikamol Muandet, Siyu Tang
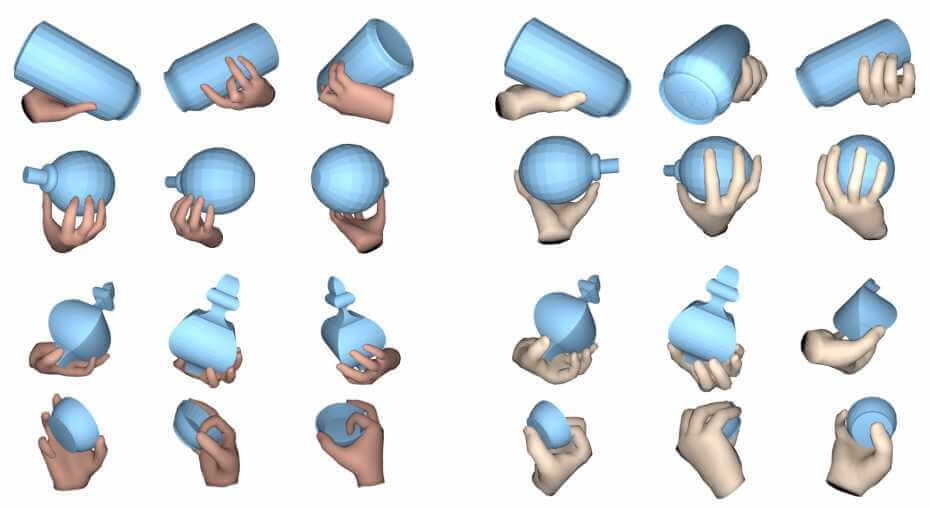
Capturing and synthesizing hand-object interaction is essential for understanding human behaviours, and is key to a number of applications including VR/AR, robotics and human-computer interaction.
Authors:Siwei Zhang, Yan Zhang, Qianli Ma, Michael J. Black, Siyu Tang
Automated synthesis of realistic humans posed naturally in a 3D scene is essential for many applications. In this paper we propose explicit representations for the 3D scene and the person-scene contact relation in a coherent manner.
Generating 3D People in Scenes without People
Conference: Computer Vision and Pattern Recognition (CVPR) 2020 oral presentation
Authors:Yan Zhang, Mohamed Hassan, Heiko Neumann, Michael J. Black, Siyu Tang
We present a fully-automatic system that takes a 3D scene and generates plausible 3D human bodies that are posed naturally in that 3D scene.