




In-depth look at our work.






Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2026)
Authors:Malte Prinzler, Paulo Gotardo, Siyu Tang, Timo Bolkart
Given calibrated multi-view images of human heads, MATCH infers static Gaussian splat textures in dense semantic correspondence.Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2026)
Authors:Yiming Wang, Qihang Zhang, Shengqu Cai, Tong Wu, Jan Ackermann, Zhengfei Kuang, Yang Zheng, Frano Rajič, Siyu Tang, Gordon Wetzstein
Time- and camera-controlled 4D video generation that enables decoupled control over world time and camera pose from a single input video.Conference: Conference on Computer Vision and Pattern Recognition (CVPR 2026)
Authors:Yutong Chen, Yiming Wang, Xucong Zhang, Sergey Prokudin, Siyu Tang
GGPT can use reliable geometric guidance to augment various feed-forward method for 3D reconstruction.Conference: International Conference on 3D Vision (3DV 2026)
Authors:Zhiyin Qian, Siwei Zhang, Bharat Lal Bhatnagar, Federica Bogo, Siyu Tang
Given a monocular video captured from a static camera, MoRo robustly reconstructs accurate and physically plausible human motion, even under challenging occlusion scenarios.Conference: SIGGRAPH Asia 2025 Conference Track
Authors:Yiming Wang, Shaofei Wang, Marko Mihajlovic, Siyu Tang
Neural Texture Splatting is an expressive extension of 3D Gaussian Splatting that introduces a local neural RGBA field for each primitive.Conference: NeurIPS 2025
Authors:Yiming Wang, Lucy Chai, Xuan Luo, Michael Niemeyer, Manuel Lagunas, Stephen Lombardi, Siyu Tang, Tiancheng Sun
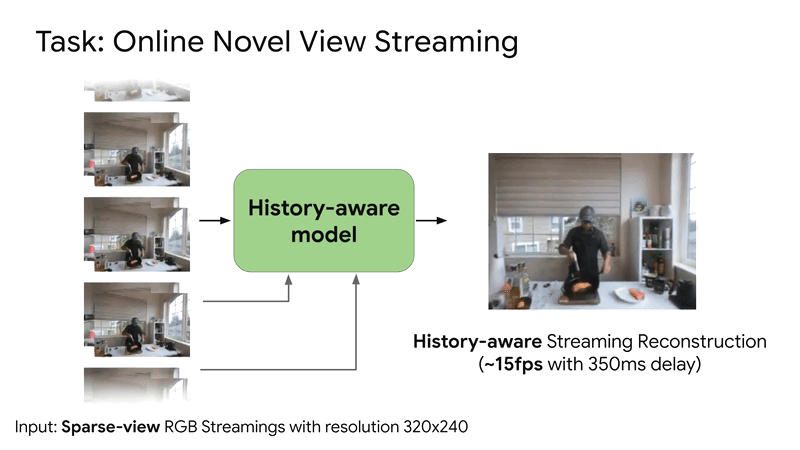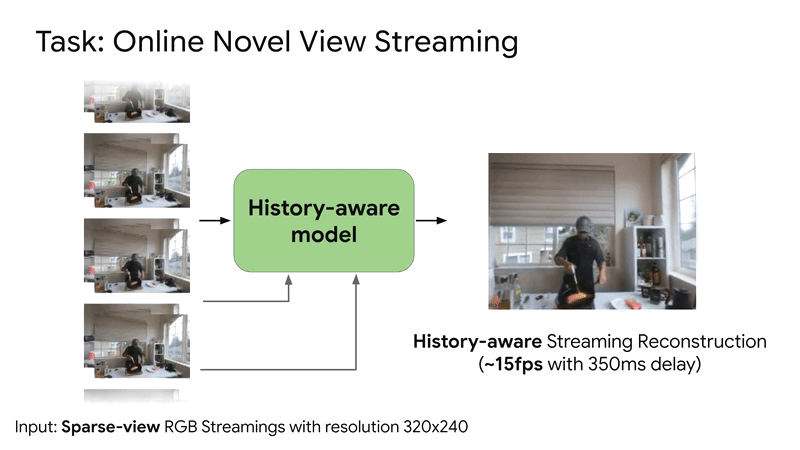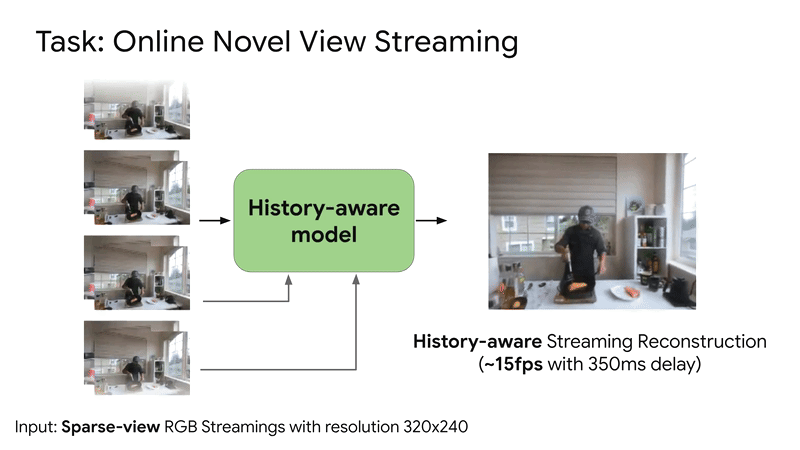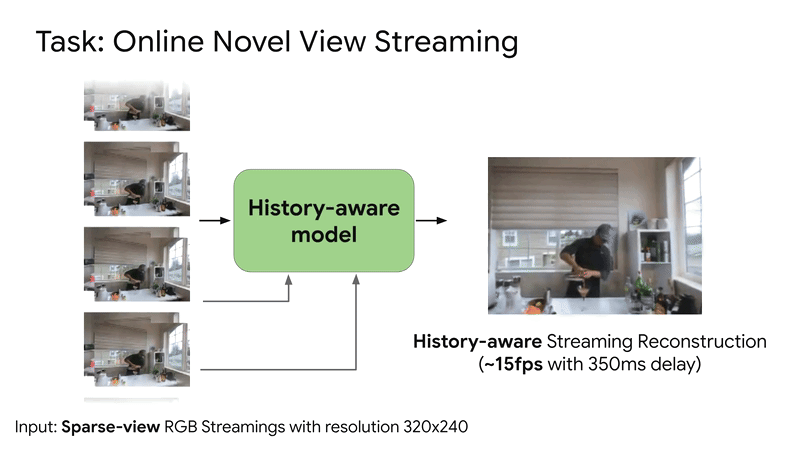
SplatVoxel is a hybrid Splat-Voxel representation that fuses and refines Gaussian Splatting, improving static scene reconstruction and enabling history-aware streaming reconstruction in a zero-shot manner.Conference: ICCV 2025 Findings Workshop
Authors:Zeren Jiang, Shaofei Wang, Siyu Tang
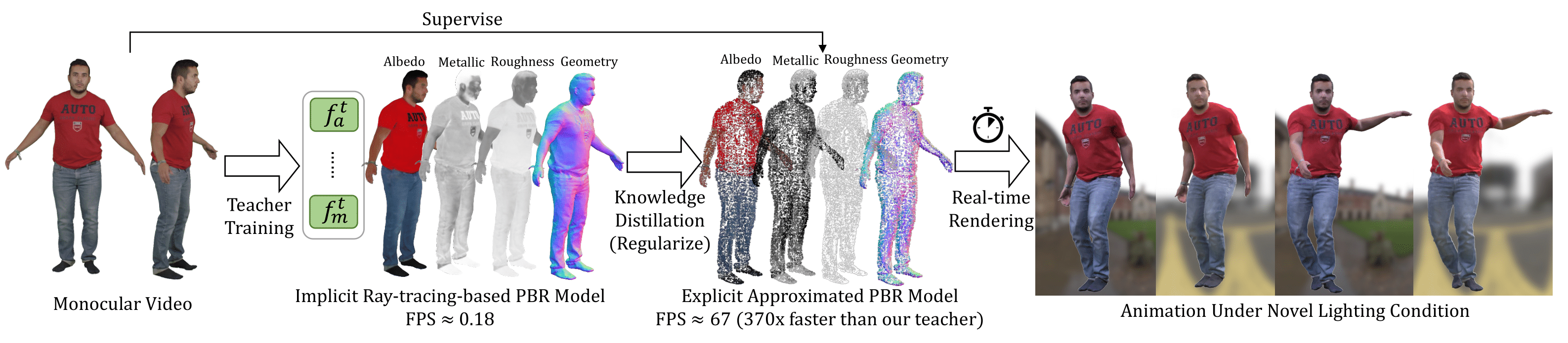
DNF-Avatar, a novel framework to distill knowledge from implicit model to explicit one for real-time rendering and relighting.Conference: International Conference on Computer Vision (ICCV 2025) highlight
Authors:Yan Wu, Korrawe Karunratanakul, Zhengyi Luo, Siyu Tang
UniPhys is a diffusion-based unified planner and text-driven controller for physics-based character control. It generalizes across diverse tasks using a single model—from short-term reactive control tasks to long-term planning tasks, without requiring task-specific training.Here’s what we've been up to recently.

We have seven papers accepted at CVPR 2024:RoHM: Robust Human Motion Reconstruction via Diffusion (oral presentation)EgoGen: An Egocentric Synthetic Data Generator (oral presentation)DNO: Optimizing Diffusion Noise Can Serve As Universal Motion PriorsMorphable Diffusion: 3D-Consistent Diffusion for...

We have five papers accepted at ICCV 2023:Dynamic Point Fields: Towards Efficient and Scalable Dynamic Surface Representations (oral presentation)EgoHMR: Probabilistic Human Mesh Recovery in 3D Scenes from Egocentric Views (oral presentation)GMD: Controllable Human Motion Synthesis via Guided...

